| |
 |
Sunday, October 25
TUTORIALS |
|
Tutorial 1: Data Center Interconnect over IP/MPLS |
Yves Hertoghs, Broadband Forum |
|
This tutorial will describe requirements and the motivation for using IP/MPLS technologies as a Data Center inter-connect technology. IP/MPLS technologies are already widespread in SP networks to deploy residential, business, wholesale, and mobile services. Data Center Interconnect is a new service SPs can offer to interconnect Enterprise Data Centers, interconnect SP Datacenters, or allow Enterprise to connect to SP-owned compute and storage power on demand. Multi-tenancy is another factor that will have it's effect on scaling characteristics of the solution.
We will describe the use of existing BGP-VPLS and LDP-VPLS as Data Center interconnect technologies, together with the enhancements needed to provide a resilient and scaleable interconnect, taking into account service instance and MAC address scaling. Additionally, this tutorial will describe the use of the relatively new EVPN technology and how it enables Service Providers to offer an enhanced Data Center inter-connect service. It will describe how EVPN supports enhanced functionality such as active-active dual site/host homing and fast service restoration in the presence of edge failures. The benefits of control plane based MAC learning using BGP will be discussed, as well as a method for hiding the Intra DC MAC-addresses from the MPLS infrastructure. We will describe and evaluate various deployment options for inter-connecting Data Centers using E-VPN. Finally, we will also describe the IETF status of EVPN.
back to tutorials ^ |
|
Tutorial 2: Cloud Architecture Approach and Considerations |
Kapil Bakshi, Azhar Sayeed, Cisco Systems |
|
Cloud computing is one of the fastest growing adoption opportunities for enterprises and service providers. Enterprises use the
Cloud model to build private clouds, and virtual
private clouds that reduce operating and capital expenses and increase the
agility and reliability of their critical information systems. Service providers build public clouds to offer on-demand, secure, multi-tenant,
pay-per-use IT infrastructure to businesses and government agencies that use cloud services to offload, or augment, their internal resources using a
public cloud infrastructure.
This session provides the cloud
model overview and describes the Cloud framework with an architecture that includes virtualization and multi-tenancy to build an end-to-end IaaS cloud-computing infrastructure. This session also provides details on Logical building blocks for cloud data centers including the virtualized network, compute, and
storage resources and its interaction with orchestration to build service differentiation. Cloud computing also drives a network connectivity model with requirements on latency for large Datacenter connectivity.
This session provides an overview of Data Center Interconnect and additional demands on the network and offers solutions on how to tackle them via the cloud centric networking model.
back to tutorials ^ |
|
Tutorial 3: Evolution of BGP and its Applications |
Yakov Rekhter, Juniper Networks |
|
Originally designed in 1989 as an inter-domain routing protocol for the Internet, over the past 22 years BGP evolved into a protocol that is used by a variety of applications, while continuing to serve its initial purpose. In this tutorial we examine the evolution of BGP from its inception (BGP-1) in 1989 until the present. We look at some of the innovations that BGP introduced in the field of protocol design. We also examine some of the controversies generated by BGP over the course of its evolution.
back to tutorials ^ |
 |
|
|
|
Monday, October 26
TECHNICAL SESSIONS |
|
Opening Speech |
Masatoshi Suzuki, KDDI R&D |
|
This abstract will be available soon.
back to program ^ |
|
Keynote Speech |
|
|
This abstract will be available soon.
back to program ^ |
|
Invited Talk - Network Infrastructure for Cloud Computing |
Yakov Rekhter, Juniper Networks |
|
This abstract will be available soon.
back to program ^ |
Break & Exhibits
10:30 am – 11:00 am |
|
Data Center Mobility: Problems and Solutions |
Rahul Aggarwal, Juniper Networks |
|
This presentation describes a set of solutions for seamless mobility in
the data center. These solutions provide a tool-kit which is based on IP routing, BGP/MPLS MAC-VPNs, BGP/MPLS IP VPNs and NHRP.
We will first describe the specific problems that need to be addressed
to enable seamless Virtual Machine mobility in the data center.
Specifically we will describe the problems of optimal intra-VLAN
forwarding with layer 2 extension, optimal Virtual Machine
gateway selection and triangular routing. We will describe the relevance
and importance of these problems in the context of data center
deployments.
We will then describe the use of "BGP/MPLS MAC VPN", which was introduced at this conference last year by the same presenter, for the purpose
of optimal intra-VLAN forwarding with layer 2 extension. This will be followed by a description of the solution for optimal Virtual Machine default gateway selection, using BGP/MPLS MAC-VPN.
Finally we will describe solutions for triangular routing. The first
solution will leverage IP routing and BGP/MPLS IP VPNs. The second
solution will leverage NHRP. We will describe various deployment
models based on these solutions.
The talk will also describe the IETF status of the data center mobility
solutions.
back to program ^ |
|
Data Center Interconnect: Multi-Homing, Resiliency and Mobility |
Clarence Filsfils, Cisco Systems |
|
This session reviews and compares different approaches to support Data Center Interconnect (eVPN, PBB-eVPN, AA-VPLS, LISP, OTV) with multi-homing, resiliency, mobility, policy and ease of provisioning. The applicability to and interoperability with the L2VPN market (VPLS) is also analyzed.
back to program ^ |
|
Virtual Subnet: A Scalable Cloud Data Center Interconnection Solution |
Xu Xiaohu, Huawei |
|
Virtual Subnet uses BGP/MPLS IP VPN technology [RFC4364] with some extensions, together with some other proven technologies including ARP proxy [RFC925][RFC1027] to provide a much scalable IP-only L2VPN service across a MPLS/IP backbone, which can be used for interconnecting data centers in a much scalable way.
The details of this solution are: PE routers use the existing BGP/MPLS IP VPN [RFC4364] protocol to exchange their own CE host routes (i.e., /32), which are automatically generated from the ARP entries of their local CE hosts, so as to built a scalable intra-subnet L3VPN service for cloud data center interconnection. Due to the ARP proxy and CE host route based explicit routing deployed on PE routers, the ARP broadcast domain and unknown unicast flooding domain of a single subnet/LAN are segmented into multiple independent parts respectively. In other words, the ARP broadcast and unknown unicast flooding will be limited within each VPN site scope, rather than across the MPLS/IP backbone. As a result, such data center interconnection solution could scale well without the concern of serious broadcast flooding impacts due to large scale subnets which may contain millions of VMs or servers.
back to program ^ |
|
PBB-EVPN: Emerging Technology for Provider Provisioned L2VPN Services and Seamless Data Center Interconnect |
Ali Sajassi, Samer Salam, Cisco Systems |
|
This presentation focuses on Provider Backbone Bridging Ethernet VPN (PBB-EVPN), an MPLS BGP-based Layer 2 VPN solution that addresses the evolving requirements in provider-provisioned L2VPN services and data center interconnect. The PBB-EVPN solution focuses on solving the following challenges: network resiliency and active/active multi-homing with flow-based load-balancing, multicast optimization with LSM, MAC address scalability via customer MAC (C-MAC) address hiding, service instance scalability for multi-tenant segmentation, virtual machine mobility as well as control plane separation between access networks or sites. The solution enables seamless interconnect of classical Ethernet in addition to next-generation data centers with Layer 2 equal-cost multi-pathing based on TRILL or the upcoming IEEE 802.1Qbq.
PBB-EVPN and Ethernet VPN (E-VPN) are emerging MPLS solutions that are being defined in the IETF in the Layer2 VPN work-group. The solutions leverage the MPLS LSP technology and its associated advantages such as scalability and fast reroute capabilities, and add extensions to perform MAC address distribution and learning over the MPLS core via the control plane (using multi-protocol BGP).
The presentation will cover a summary of the evolving requirements for L2VPN services and data-center interconnect, an overview of PBB-EVPN, the components of the solution, its advantages over other MPLS-based L2VPN technologies, in addition to relevant network use-case scenarios.
back to program ^ |
Lunch & Exhibits
12:30 – 2:00 pm |
|
Enabling Seamless MPLS using LDP Downstream on Demand |
Thomas Beckhaus, Deutsche Telekom, Kishore Tiruveedhula, Maciek Konstantynowicz, Juniper Networks
|
|
Seamless MPLS design approach enables a single IP/MPLS network to scale over core, metro and access parts of a large network infrastructure using standardized IP/MPLS protocols, as described in draft-leymann-mpls-seamless-mpls. The key goal of Seamless MPLS is to address access network requirements, specifically to restrict the extend of IP/MPLS protocols implementation on access nodes and limit the amount of state that access nodes have to hold.
This talk describes a real-world network design based on Seamless MPLS concepts. The presentation shows how LDP Downstream-on-Demand (DoD) can be used to meet the access network requirements, followed by description of LDP DoD operation in the context of the network case study. Focus is on the main usability and operation properties of target LDP DoD implementation. Number of use cases are covered, including infrastructure provisioning, through service provisioning and operation, and handling of failure cases. Interaction with IP routing and other MPLS label distribution protocols is described. LDP DoD implementation optimization aspects are discussed.
back to program ^ |
|
UNIFIED MPLS - How can MPLS Span Smoothly E2E in the Network and Which Role Does the Control Plane Play? |
Elisa Bellagamba, Ericsson |
|
In recent years the idea of building an end-to-end Transport network based on a common underlying technology across both Fixed and Mobile has emerged. By doing so, operators will be able to streamline operations and more efficiently offer services. MPLS has emerged as the consensus candidate for this common underlying technology, as it is the only technology which is able to provide the efficiency and scale of packet networks while also meeting transport requirements.
As this common end-to-end network based on MPLS develops further, the biggest challenge operators will face will be the problem of scale. The sheer number of nodes in this new network will far surpass anything that has been built in the past. This is because previously diverged networks were subject to divergence between the different technology choices (ATM, SONET/SDH, PDH, Ethernet, IP, MPLS) as well as separation between different operating domains (for example Fixed versus Mobile) within the organization, which reduced the scale of any single portion of the network. Thus there is now the need to define a new type of network architecture that is built to scale for the needs of a converged operator who is looking to build and operate one network to carry all of its services.
back to program ^ |
|
Architecture Options for Designing Highly Scalable and Reliable MPLS Networks |
Mustapha Aissaoui, Adam Simpson, Alcatel-Lucent
|
|
As MPLS footprint is expanding into the access and aggregation networks, the network must be architected to provide connectivity and resilience to a large number of PE/P routers. One of the main challenges is that routers used in the access network are smaller, feature limited, and have much less processing power and memory than those used in aggregation and core parts of the network. This presentation will describe a number of architecture options which allow the extension of MPLS into access network while keeping routing tables and MPLS label forwarding tables in the smaller access routers to a reasonable size. It will also discuss local and end-to-end resilience schemes to address the challenge that link and node failures cause a longer convergence time for the control plane protocols due to the span of the network. Finally, it discusses a number of design options for delivering L2 and L3 services over such a network.
back to program ^ |
|
Design and Implementation of OpenFlow-Based MPLS Controller for Access/Aggregation Networks |
Kiran Yedavalli, Ramesh Mishra, Ravi Manghirmalani, Mallik Tatipamula, Ericsson
|
|
In today’s service provider networks, MPLS is mainly used in the core of the network. Seamless MPLS is an emerging paradigm where MPLS is extended to a service provider’s access and aggregation network as well. The routers and switches currently being used within an MPLS network work with each other in a distributed fashion. This distributed network architecture, which we call traditional network architecture, inherently presents some challenges. These include high cost of deployment, high cost of software upgrade and maintenance, and very slow service velocity among others.
An emerging network architecture called the split architecture is increasingly being seen as a very good alternative to the traditional network architecture to address the above mentioned challenges effectively. In the traditional network architecture, every forwarding element (e.g. Router, Switch) in the network has its own control plane and data plane functionality. In contrast, in the split network architecture, while the data plane functionality still resides on the forwarding element, the control plane functionalities of all the forwarding elements are centralized at a single central location. Split-architecture inherently allows independent optimizations of the control and forwarding planes, in terms of cost, scalability, reliability, service deployment, etc.
In this paper, we present our work on design and implementation of a network controller based on the split architecture paradigm. In this work, we discuss the access/aggregation networks’ specific controller applications that we developed over a distributed network middleware based on OpenFlow 1.1 specification. The distributed middleware provides an abstraction of the network graph in the form of APIs that allow network programmability by the controller applications. The applications we developed provide IP/MPLS LSP setup capabilities and Pseudowire service setup capabilities to the network controller. Further, we discuss in detail the mechanisms we developed to make the split architecture networks work in tandem with the traditional networks. For the forwarding switches, we use multiple OpenFlow 1.1 enabled devices including an OLT (fiber-tohome scenario), an aggregation device, and a general purpose multi-core programming platform.
back to program ^ |
Break & Exhibits
3:30 pm– 4:00 pm |
|
SP Cloud Computing: Services, Architecture and Standards Considerations
|
Monique Morrow, Cisco Systems |
|
Traditional SPs are in a unique position to provide SP and Enterprise grade Cloud services to its customers. For example, with PPVPN, end/edge-to-end-edge (E2E) QoS, etc., an SP can provide secure and SLA ready Cloud services. Features such as CsC, multi-provider MPLS VPN can facilitate Inter-Cloud and multi-provider Virtual Private Cloud. The MPLS network is therefore table stakes as a foundation, e.g., network abstraction and virtualization to developing cloud services.
However offering cloud services on top of these capabilities is not without challenges, e.g., decomposing real time mechanisms and elastic requirements that are often associated with cloud computing service delivery.
Finally, the speaker will conclude the presentation with an overview of the standards/forum landscape that includes IEEE, ITU-T, NIST, TM Forum, DMTF and so on.
back to program ^ |
|
End-to-End Cloud Networking across Multi-Layer Networks |
Lubo Tancevski, Alcatel-Lucent
|
|
Cloud networking is rapidly gaining importance due to its promise to revolutionize the way IT and development resources are being utilized. It enables a complete “pay as you go” paradigm and promises to substantially reduce costs. At the heart of cloud networking is a set of technologies such as virtualization that enable resources to be provisioned and managed elastically, and therefore consumed more efficiently and on demand. This, in turn, requires networking infrastructures to be even more dynamic, with automated provisioning and operation. Computing services must also scale to tens of thousands distributed across the wide area, with support for complete end-to-end SLAs and seamless integration of data centers with multi-layer service delivery networks. Multi-layer networks must be architected to meet these requirements for effective cloud computing. This paper will first examine the requirements and architectures for cloud networks, (centralized, distributed, federated, with support for SAN networks). It will then analyze how dynamic, elastic, and traffic engineered connections subscribing to various constraints and fulfilling the SLAs can be provisioned and operated in multilayer networks. The requirements on the GMPLS control plane and the UNI will also be analyzed. Emphasis will be also given to providing efficient support for VMotion with IP/MPLS, as well as integrated support for SAN applications. Network scalability, resiliency, operations, and troubleshooting will also be analyzed.
back to program ^ |
|
Application and Service Aware IP/MPLS Networking |
John Evans, Cisco Systems |
|
Cloud computing is revolutionizing the delivery of IT services and is driving many service providers to augment their portfolio with cloud-based services. In response, service providers are seeking to support the rapid deployment of new cloud services and applications with stringent service level agreements for network performance, while simultaneously making efficient use of their network infrastructures, i.e. without gross over-provisioning. This transition must be achieved in an environment that is dynamically changing with moving workloads and in the presence of failure and recovery events.
Historically, however, IP/MPLS networks, and the applications and services that use the networks, have only been very loosely coupled via capacity management processes. The emergence of high bandwidth, high demand volatility applications and services - such as cloud computing - is challenging the limitations of these approaches. As a result, new technologies are emerging which provide much closer and more responsive coupling between services and applications and the underlying IP/MPLS transport network.
In this presentation we consider how new technologies, such as ALTO, are enabling application and service aware IP/MPLS networks to meet the challenges of service such as cloud computing, with use cases illustrating how they are practically used in Service Provider networks and the benefits these new technologies offer.
back to program ^ |
|
|
|
|
|
Panel Topic: Role of MPLS and Ethernet Network Technologies as Enablers to Cloud Computing |
|
|
The participants will discuss the role of MPLS and Ethernet across a private MPLS backbone vs offering Cloud-based services over the Internet. What is the role of the network, specifically technologies like MPLS and Ethernet? What are the challenges and opportunities specifically to the data center in the context of cloud computing? What should be the role of standards? Finally, what is the call to arms for the industry?
back to program ^ |
|
|
|
|
Tuesday, October 27
TECHNICAL SESSIONS |
|
Standards Update |
Loa Andersson, IETF, Ericsson |
|
back to program ^ |
|
Multi-path LSPs Signaled Using RSVP-TE |
Kireeti Kompella, Juniper Networks |
|
There are two predominant approaches to unicast MPLS backbone engineering, exemplified by two protocols for creating MPLS tunnels. One, using LDP, creates multipoint-to-point shortest path tunnels. This approach allows hop-by-hop Equal Cost Multi-Path (ECMP); that is, at each hop, an LSR may choose one of several paths to send packets to a given destination. However, LDP does not allow bandwidth reservation or traffic engineering.
The other, using RSVP-TE, creates point-to-point tunnels. RSVP-TE tunnels can be traffic engineered, can have bandwidth reservations, and can use link coloring and Shared Risk Link Groups to control tunnel placement. However, multi-pathing is very coarse: the ingress LSR chooses one of possibly several tunnels that lead to the destination; but once packets are placed in a tunnel, they follow a fixed path.
This talk will present an approach that enables multi-pathing with traffic engineered tunnels. It will describe the basic idea, and outline some of the benefits. It will then show several variants with regard to bandwidth management and path placement. It will also show how the notion of entropy labels can be folded in to improve load balancing behavior.
Technical details of the concept can be read in the IETF draft draft-kompella-mpls-rsvp-ecmp.
back to program ^ |
|
Multiservice Broadband Access |
David Allan, Ericsson |
|
The evolution of broadband access networks is leading to convergence of multiple services/business units on a common infrastructure. While the economies of scale of a single infrastructure build can be leveraged, what this frequently means is that service platforms are specific to and operated by distinct business units.
This places new virtualization and QoS demands on the network while seeking to preserve operational simplicity. The simplest expression of the requirement being that any customer facing port can be mapped to any service platform in the network with consistent QOS, OAM and craftsperson access while minimizing the number of touch points for adds moves and changes.
The multi-service-edge architecture discussed in this presentation combines Ethernet access and aggregation combined with MPLS to achieve a cost effective and forward looking converged infrastructure based on a combination on DSL, PON, and p2p fiber access. The architecture permits arbitrary placement of service nodes, utilizing MPLS PWs as a virtual steering/grooming mechanism. What standardization efforts in the IETF, BBF and MEF combine in the realization of this architecture are also discussed.
back to program ^ |
|
Efficient Multicast with mLDP in-band Signalling |
Nicolai Leymann, Deutsche Telekom,
IJsbrand Wijnands, Cisco Systems |
|
Due to the growing IPTV offers deploying IP-Multicast for Live TV many ISPs are looking into MPLS based Multicast solutions. mLDP in combination with in-band signalling provides a flexible MPLS based solution. The presentation will give an detailed view into the following topics:
- MPLS based Multicast with mLDP in-band signalling: Description of the technical details of mLDP in-band signalling and its advantages.
- The IPTV Use Case: The requirements and characteristics of the IPTV use case of Deutsche Telekom. This covers scalability aspects (like number of source and number or Multicast P2MP trees, the need for redundancy, …). Operational issues (e.g. SSM mapping in case of ASM only applications) and the relationship with the existing Seamless MPLS implementation.
- Network Architecture: The network architecture and implementation deploying mLDP in combination with in-band signalling. The implementation options for dynamic and non-dynamic Multicast scenarios as well as a solution for moving towards a controlled Multicast virtualization on top of mLDP.
back to program ^ |
Break & Exhibits
10:30 am – 11:00 am |
|
Evolution of MPLS-TP and MPLS-TE |
George Swallow, Zafar Ali, Cisco Systems |
|
With the addition of a control plane, MPLS-TP will take on the dynamic characteristics and some of the functionality of MPLS-TE. This talk will explore the similarities and differences in the two technologies. The speaker will note where each is applicable. Finally, the speaker will examine how each can benefit from incorporating features of the other, pointing towards a convergence of the two technologies.
back to program ^ |
|
MPLS-TP Reality Check: Pre-Deployment Milestones and Best Practices |
Andrew Malis,Verizon, Tara Van Unen, Ixia,
Luyuan Fang, Cisco Systems |
|
In today's business scenarios, one of the biggest challenges for Mobile Operator is to achieve High QoE at minimum OpEx and CapEx cost. With emergence of smart devices such as Smartphone and Tablets, new types of service and technology are emerging at exponential rate. MBB is logically divided into three main segment - Radio Access, Backhaul and Core Network, in which backhaul have maximum OpExa and CapEx. So, Mobile operator are forced to rollout IP/Metro-Ethernet based solution in Backhaul and Core network to retain their existing customer and enter into new customer market segment. To optimize ROI, Mobile operator are looking for such technology which protect the investment on traditional network equipment like SONET/SDH, ATM, Frame Relay and T1/E1.
MPLS and its derivatives like GMPLS, MPLS-TP, L2VPN, L3VPN and PWE are designed to transport any service over any transport, and to combine multiple services over a common transport, whilst providing appropriate QoS for each service. MPLS framework is ready to accept new challenges like high availability, OAM and Security Tunnel Creation.
This paper describes the mechanism to rollout MPLS-TP in mobile backhauls, reuse traditional backhaul technology on IP/MPLS based core network and E2E QOS for maximum QoE. MPLS-TP provides complete solution by consolidating MPLS, L2VPN and PWE3 along with OAM functionality. MPLS is very successful technology in core Network with inbuilt IP QoS, Fast-Re-route, and pre-Established path. But addition of OAM functionality has made MPLS-TP solution as first choice for mobile broadband operator. MPLS-TP is designed to migrate/inter-work smoothly from legacy network to new IP based backhaul and core without any additional cost.
This paper also discuss mechanism create secure tunnel by encapsulating MPLS Header inspite of IP Header as defined in current itef standard.
back to program ^ |
|
Interoperability or Interworking? Using MPLS-TP Functions in IP/MPLS Networks |
Matthew Bocci, Alcatel-Lucent |
|
The MPLS Transport Profile promises not only to enable MPLS to be deployed in optical transport networks, but also to add new features to existing MPLS networks to allow them to support packet transport services with a similar degree of predictability to those found in existing transport networks. This talk will look at the value that these new features bring to IP based MPLS networks, in particular when services are deployed on a combination of optical transport and IP equipment. We will look at whether MPLS-TP OAM and protection need to be extended to the IP based MPLS network, and in what deployment scenarios. The presentation will compare and contrast these new features versus existing MPLS functionality, discussing what these enhancements mean to MPLS outside of the typical transport operational domain, and analyzing where they add value to typical MPLS metro and core deployments.
back to program ^ |
|
Packet Transport Network Design with MPLS-TP |
Luyuan Fang, Cisco Systems |
|
This session will cover:
• Cost saving analysis for transport moving from TDM to Packet transport
• MPLS-TP technology components and Standardization
• NGN design trend: moving from isolated transport networks toward end-to-end MPLS solutions
• Real world deployment scenarios
• Network design considerations:
• Static provisioning vs. GMPLS dynamic control plane;
• LSP and PW protection options
• Multi-homing with protected paths
• Multi-layer protection switching coordination
• GMPLS control for MPLS-TP provisioning and recovery
• The importance of consistent MPLS OAM from core to access
back to program ^ |
|
Separated Architecture of Packet Transport and Services |
Takeshi Shibata, Kenichi Sakamoto, Masayuki Takase, Kiyotaka Takahashi, Daisuke Mashimo, Yoshihiro Ashi, Akihiko Takase, Hitachi |
|
We have investigated the deployment scenario of packet transport technologies into carrier networks.
In this presentation, we focus on two major requirements in carrier networks. The first one is stability and the other is flexibility. The requirements for the stability come from the long period of experience on fixed, conventional transport layer technology, such as SONET/SDH. On the other hand the flexibility is required for router layer, such as IP and routing protocols, which is essential for constructing the dynamically configurable networking systems.
We have considered two approaches for deploying packet transport into carrier networks; integration approach and separation approach.
The integration approach is to support both stability and flexibility as the roles of transport and router layers in packet transport environment. There is some possibility of decreasing operational complexity. The stability as well as the flexibility based on blind to flapping are to be put together in packetized information transports, there must be some difficulties for realization.
The separation approach is to take the stability as the most prominent aspect in packet transport environment. The role of transport layer and the role of router layer are to be constructed separately. There is every possibility of using operational knowledge and skill, because the layered architecture in present carrier networks is not changed.
Our suggestion is to take the separation approach as the first step, since the deployment of packet transport becomes easier and the improvement of network performance, operational ability and OAM related functions, e.g. monitoring, protection and so on, will become more obvious utilizing transport layer and router layer as they are.
This presentation will describe the consideration of adapting the information of router layer to transport layer with separation of transport and router layers, so as to deploy separated architecture of packet transport into carrier networks with synergy between transport and router layers. We developed the prototype of this separated architecture. The results have revealed the success of reducing additional operational cost. We will address the challenges and solutions in packet transport networks based on separated architecture.
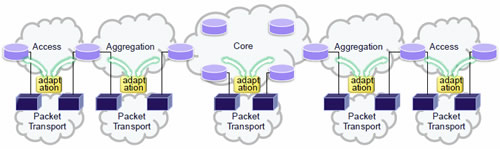
Fig. Separated architecture of Packet Transport and Services
back to program ^ |
Lunch & Exhibits
12:30 – 2:00 pm |
|
Towards 100% FRR Backup Coverage for IP/LDP Networks |
Hannes Gredler, Juniper Networks |
|
The lack of 100% backup coverage is one of the major shortcomings of
IP/LDP FRR (by means of Loop-free alternate calculation) technology and
remains a major obstacle for widespread rollout.
Most existing LFA implementations allow to manually engineer the
topology using RSVP LSPs, such that path backups can be found and
backup coverage is thereby increased.
This has two major disadvantages:
First this is a manual process and therefore tedious, lagging
and error-prone to maintain.
Second it does create additional data-plane state in the network,
which impacts the scaling of MPLS transport networks.
This talk is about a novel method which automatically builds backup
paths by reusing existent primary paths in the network. Contrary to
Loop free alternate based IP/LDP FRR schemes (which only use the
immediate 1-hop neighborhood), this method may use any node in the
network as a potential "backup-forwarder". It is paramount that
connectivity to the backup-forwarder is loop-free and therefore
techniques to avoid forwarding loops without creating any new MPLS
dataplane requirements will be highlighted.
The talk will be complemented by a backup coverage analysis of
real world tier-1 service provider topologies, demonstrating that
100% backup coverage for IP/MPLS transport networks is feasible.
back to program ^ |
|
IPFRR based on Fast Notification |
András Császár, Gábor Enyedi, Attila Takács, Jeff Tantsura, Ericsson |
|
IP Fast Re-Route (IPFRR) has gained industry attention as a potential technology to facilitate sub 50 ms fail-over in IP and MPLS networks without the need for RSVP-TE protection. Loop Free Alternates (LFA) is the deployed IPFRR solution, which, however, cannot protect all possible failure cases in arbitrary network topologies. It provides in average ~80% failure coverage. In some failure scenarios a node not adjacent to the failure has to route packets heading to a destination differently before and after the failure, such as in a sub-topology consisting of a ring longer than a triangle. Such remote nodes must receive some sort of trigger or information to react. LFA cannot handle such failures.
Fast Notification (FN) [1], which has recently been proposed to the IETF as a lightweight network event dissemination solution, can notify all nodes in the network (IGP area) about various events. The per-hop forwarding of FN packets, opposed to the IGP link state message flooding process, does not take much more time than plain fast path multicast forwarding: it can be as low as recognizing a well known multicast address denoting that the packet is not only to be multicasted but it also needs attention locally (i.e. punting it for processing).
In this presentation we would like to show that applying a fast and lightweight failure notification protocol, such as FN, enables a new and advantageous fast fail-over mechanism [2]. The concept of our proposal is the following: The Control Plane pre-calculates alternate routing configurations in preparation for local and relevant remote failures and pre-installs failure specific backup routes in the Forwarding Plane (FP). These remote backup routes can be activated by fast notifications describing the failure, originated and processed within the FP. When applying FN for disseminating failure information, FN has to be configured in such a way that notifications reach all routers despite a failure in the network. This can be achieved by distributing FN over dual redundant trees or by doing controlled flooding which are discussed in the presentation.
Gains of IPFRR based on Fast Notification include:
- 100% failure coverage in arbitrary topologies;
- In addition to single link and single node failures, it can address SRLG failures.
- IPFRR detour paths would in most cases be identical to the path after IGP convergence;
- Reduction of control plane stress during re-convergence, since there is no need to perform the pre-calculations again;
- Running in the FP, the FN protocol also works in split architectures;
- Besides IPFRR, FN enables innovation for future applications that would require quick network event dissemination in an area.
In the presentation, we explain the proposed concept and its gains, and discuss the feasibility and scalability of the solution. We explain the complexity of calculating area wide remote backups and prove that failure specific backups are rather tolerable. We present performance measurements obtained from our prototype implementation.
References:
[1] W. Lu, S. Kini, A. Császár, G. Enyedi, J. Tantsura, A. Tian: "Transport of Fast Notification Messages", IETF draft-lu-fn-transport, Work in progress!
[2] A. Császár, G. Enyedi, S. Kini: "IPFRR based on Fast Notification", IETF draft-csaszar-ipfrr-fn, Work in progress!
back to program ^ |
|
50ms Layer-3 VPN Service Restoration |
Minto Jeyananth, Juniper Networks |
|
When the links or nodes fail in the provider core network, such
existing local repair based mechanisms as Loop Free Alternative(LFA)
or RSVP FRR can be used to protect transport LSP, which could
help to achieve fast connectivity restoration for VPN service.
However, if the failure happens in the provider edge (PE node
failure) then these existing mechanisms are not applicable. The
proposed solution closes this gap. It provides FRR-like local
repair for egress PE failure, thereby enabling fast connectivity
restoration for VPN service in the presence of either transport
or edge failures.
An important feature of the proposed solution is that unlike
global repair based approaches, which rely on propagating control
plane notifications during the failure to restore VPN service,
service restoration in this proposal does not depend on propagating
control plane notifications, as it is based on the local repair,
and therefore is faster (sub 50 ms) and more deterministic than
any global repair based approach.
The proposed solution is built on extending the approach of local
protection for LSP tail-end node failure that was presented by
Y. Rekhter as an Invited Talk in MPLS 2009 Conference. We will
share the detailed implementation of the solution, as well as
the performance results based on our implementation of the solution.
back to program ^ |
|
Setup Protection of MPLS LSPs |
Yimin Shen, Nitin Bahadur, Harish Sitaraman, Rahul Aggarwal, Juniper Networks |
|
RSVP-TE signaled MPLS LSP can be successfully set up only if the entire path is up and the signaling constraints are satisfied.
In various network deployments, such as transport and video distribution networks, the path of LSP may be pre-computed and fixed.
In applications like event based data transfers and timed video broadcast, there is a requirement that the LSP shall come up, even if
there is a network failure, as long as there is a bypass LSP protecting the failed link or node.
With current RSVP-TE mechanisms, protection of un-established LSPs is not possible. In this presentation, we will introduce an
extension of facility-backup fast reroute that can provide “setup-protection” for P2P and P2MP LSPs. If there is a link or node failure
on the intended path of an LSP during RSVP-TE Path message signaling, and if there is a bypass LSP protecting the link or node,
RSVP will signal the LSP via the bypass LSP and bring up the LSP. Thus, one will be able to set up immediate or timed LSPs over failed
links or nodes. These LSPs set up over bypass LSPs will eventually revert to their original primary paths, once the network failure
is resolved.
back to program ^ |
|
Fast MPLS TE LSP End to End Protection |
Huaimo Chen, Huawei |
|
In this presentation, we first analyze the existing solutions for the MPLS TE LSP protections, which include the end-to-end protection. Then we propose a new method for locally protecting both the ingress node and the egress nodes of an MPLS TE LSP, which can be an MPLS TE P2MP LSP or an MPLS TE P2P LSP. The new method with the existing MPLS TE LSP FRR for protecting intermediate nodes and links forms a fast MPLS TE LSP end-to-end protection. Moreover, we illustrate the advantages of the new protection method through comparing it with the existing solutions from service providers’ point of view.
There are following issues in the existing solutions for MPLS TE LSP end-to-end protection:
- Not scalable. Double or more numbers of end-to-end MPLS TE LSPs are used.
- Consume lots of resource. Double resource such as bandwidth is reserved or used.
- Not reliable. In some cases of MPLS TE P2MP LSP protection, the failure of reverse P2P LSP from leaf to root does not mean the failure of its corresponding P2MP sub-LSP from root to leaf.
- Failure recovery is slow in some cases. The speed of an ingress or egress node failure recovery may depend on the convergence of IGP and BGP.
- Difficult to configure and maintain.
The new method for MPLS TE LSP end-to-end protection resolves all the above issues.
back to program ^ |
Break & Exhibits
3:30 pm – 4:00 pm |
|
MPLS-Based Mobile Backhauling for LTE-Advanced |
Nicolai Leymann, Deutsche Telekom |
|
The integration of Mobile Backhaul for LTE/LTE Advanced into existing MPLS networks is one of the major challenges for the next years. Several options do exist (e.g. L2VPN, L3VPN, …) and need to be considered when implementing a Mobile Backhauling solution taking the requirements of LTE/LTE advanced into account.
This presentation explains and compares the different approaches and will cover the following topics in detail:
- Network Requirements for LTE/LTE Advanced: Detailed description of the network requirements which need to be fulfilled by a Mobile Backhaul solution for LTE. This includes QoS support, Unicast and Multicast support, traffic patterns and mobile interfaces (X2, …) as well as the communication behavior and delay requirements.
- Solution Space: The different approaches for integrating Mobile Backhaul into an existing MPLS network are described and compared. This takes the (limited) MPLS capabilities of the Mobile Access network into account; management aspects (e.g. independence of IP addressing) and the differences between an L2 and L3 based solution (L2VPN/VPLS and L3VPN).
- Network Architecture: Detailed description of the approach Deutsche Telekom is using for the integration of Mobile Backhaul into the existing MPLS network.
back to program ^ |
|
MPLS has Addressed the Mobile Backhaul Challenge |
Pierre El-Hadad, Alcatel-Lucent |
|
MPLS has lived up to its initial promise to cost effectively evolve networks to All-IP. First in the backbone, and now in the backhaul. Mobile operators and Backhaul Transport Providers globally have evolved their networks to All-IP backhaul networks reducing 2G/3G backhaul costs, and also setting the foundation for rapid LTE deployment. This talk highlights experiences gained by Alcatel-Lucent in deploying its Mobile Backhaul solution globally.
Key elements that will be covered include:
• Leveraging existing networking assets while providing the required path for the future
• Building capacity and scalability for mobile backhaul growth
• Ensuring synchronization distribution
• Providing resilient architectures
• Guaranteeing performance
• Enhancing operational benefits
back to program ^ |
|
Putting IP/Ethernet Mobile Backhaul Resiliency and Performance to the Test |
Sailaja Tennati, Spirent |
|
Driven by smartphones and video consumption, globally, mobile data traffic nearly tripled in 2010 and IP traffic is projected quadruple between 2009 and 2014. This increased traffic in the mobile backhaul is stretching the traditional TDM transport beyond its capabilities.
Most of the new content is packet-based, but legacy transport solutions such as SONET/SDH and OTN are more suited for circuits. The new content requires more efficiency in transmitting packets. Consequently, adding new TDM backhaul circuits is more expensive per port and per bit than packet-based alternatives. In order to remain profitable, operators are being forced to migrate to a packet based mobile backhaul.
While an Ethernet based packet transport is efficient and cost-effective, it lags TDM in monitoring, fault management and protection switching capabilities. Enter MPLS-TP. In a joint effort between ITU and IETF, the MPLS-TP standards have been developed to ensure that MPLS-TP retains the packet efficiencies of IP/MPLS and the OAM capabilities of TDM. Network equipment manufacturers (NEMs) around the world are updating their access and transport nodes to support a) static MPLS-TP connections, b) Continuity Checking/Connectivity Verification (CC/CV) procedures and c) Fault management and protection switching capabilities. These capabilities are ultimately needed to ensure QoS/QoE for end users and for sub-50 ms switchover of failed network nodes.
In these beginning stages of MPLS-TP deployment, it is important for NEMs and service providers to test the OAM capabilities of their MPLS-TP enabled nodes. It is not sufficient to just test traffic forwarding or BFD/Y.1731 based OAM procedures across MPLS-TP connections. It is crucial to test MPLS-TP forwarding at line-rate, to test CC/CV and fault management procedures on thousands of connections simultaneously and to test all of the aforementioned procedures at 3.3 ms CC heartbeat frequencies. Finally, it is important to ensure the convergence of data traffic on the protection path within 50 ms of the failure of the primary path. Lack of rigorous testing can lead to significantly more expensive failures in the field and lost revenues from mobile subscriber churn.
During this presentation Spirent will discuss and share test methodologies that will enable NEMs and service providers to easily emulate complex mobile backhaul topologies and test MPLS-TP OAM and interoperability with IP/MPLS.
back to program ^ |
|
Panel Topic: MPLS vs Ethernet Technologies in Support of Data Centers |
|
|
With the latest Ethernet technology development, which improved layer 2 network redundancy with various ring prevention protocols such as 8032v2, Trill, 802.1aq, the layer 2 control plane is moving closer to layer 3. Have Ethernet and MPLS become equals in term of providing connectivities and services?
Does data center solution benefit from MPLS technology, or Ethernet technology on any specific area? for example in terms of plug and play; auto-discovery of resources; load-balancing, controllable delay, redundancy, geographical coverage, scaling consideration.
back to program ^ |
|
|
|
|
Wednesday, October 28
TECHNICAL SESSIONS |
|
A Multi-Domain PCE Framework for QoS-Aware Global Path Provisioning |
Akeo Masuda, Akinori Isogai, Aki Fukuda, Rie Hayashi, Kohei Shiomoto, Atsushi Hiramatsu, NTT |
|
|
Network Virtualization is a technology to construct logical network topologies using a set of network resources that are virtually extracted from the physical network. Previously we have been working on the development and experiments of our virtualization architecture based on PCE and VNTM technologies. Upon a single IP-optical network, we have succeeded in allowing the virtual network operators to control each portion of the network individually but simultaneously by allocating the virtualized slice of the resources such as wavelengths, OXCs and IP routers.
On the other hand, NRENs (National Research and Education Networks) are developing the standard of on-demand provisioning of bandwidth guaranteed datapaths that traverses multiple network domains. Our next challenge is to enhance our virtualization architecture by integrating with this multi-domain path provisioning technologies, in order to provide a world-wide logical network by cooperative virtualization between multiple network domains. Furthermore, some testbeds for development of future networking technologies are working on open and shared framework of the network performance monitoring. By employing dynamic performance measurements, we can choose the best inter-domain path to form an edge of the virtual network in advance, or switchover to a path that can offer better QoS when fluctuation of the performance had been detected. This kind of technology can be expected to accelerate the global and high quality communication service such as IP based broadcasting and world-wide VPN.
The first step in our research aims is to establish the overall architecture and some of the essential technologies for provisioning global datapaths that satisfies the user’s QoS requirements. In our presentation, we address the functional requirements, related works, and give discussion on the technical issues such as inter-domain resource allocation, signaling model, servers and protocols, sharing performance measurements, optimal path selection algorithm and loss-less path switchover concerning the performance fluctuation. We also show the results of the experiments of dynamic path provisioning and performance measurements, which conducted in collaboration with several NRENs that provide capability of DCN (Dynamic Circuit Network), and also introduce our next plan of experiments on global path selection, provisioning and measurements employing latest technologies such as high-resolution perfSONAR and NSI connection service protocol.
back to program ^ |
|
Protocol Extensions and Seamless Interworking Between PCE and GMPLS for Reliable and Dynamic WSON |
Lei Liu, Takehiro Tsuritani, Itsuro Morita, Kenichi Ogaki, Ramon Casellas, Ricardo Martínez, Raül Muñoz, KDDI |
|
Wavelength switched optical networks (WSON) are wavelength division multiplexing (WDM) based networks which include switching elements that can switch signals transported over optical fibers, according to the wavelength or the frequency of the signals. To better address the requirements of WSON, the IETF Common Control and Measurement Plane (CCAMP) and Path Computation Element (PCE) working groups are actively promoting the standardization of PCE and GMPLS for the intelligent control of WSON [1-8].
In this talk, we report a successful implementation and deployment of PCE/GMPLS controlled WSON testbed with both control plane and data plane. We introduce protocol extensions to both PCE and GMPLS. Some of them are derived from the proposed standards [1-8] and some of them are vendor-specific in order to better address the impairment-aware routing and wavelength assignment (IA-RWA). We also achieve the seamless interworking between PCE and GMPLS controllers on the testbed, as shown in the following figure, which facilitate the dynamic path computation, lightpath provisioning and service restoration.
Firstly, we summarize the protocol extensions and our implementation works on GMPLS and PCE for WSON. After that, we elaborate the interworking between PCE and the GMPLS controller with aforementioned extensions. Finally, we report our latest experimental results in both single domain and multi-domain WSON testbed, including the path computation latency, lightpath provisioning latency, and service recovery time by using PCE-based pre-planned restoration and dynamic restoration.
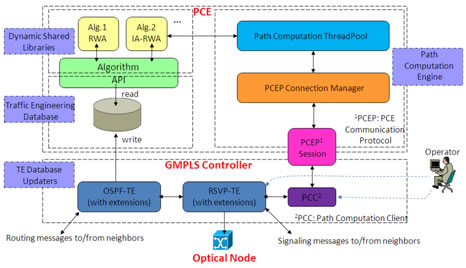
References [1] Y. Lee, et al, IETF RFC 6163, Apr. 2011. [2] T. Otani, et al, IETF RFC 6205, Mar. 2011. [3] Y. Lee, et al, draft-ietf-ccamp-wson-impairments-07, work in progress, Apr. 2011. [4] G. Bernstein, et al, draft-ietf-ccamp-rwa-wson-encode-11, work in progress, Mar. 2011. [5] Y. Lee, et al, draft-ietf-ccamp-rwa-info-11, work in progress, Mar. 2011. [6] A. Farrel, et al, IETF RFC 4655, Aug. 2006. [7] JP. Vasseur, et al, IETF RFC 5440, Mar. 2009. [8] Y. Lee, et al, draft-ietf-pce-wson-routing-wavelength-05, work in progress, Jul. 2011.
back to program ^ |
|
Software Defined Network Toward C&C Cloud
|
Soichiro Araki, Itaru Nishioka, Toshiyuki Kanoh, NEC |
|
The world of cloud computing has been greatly changing. "C&C Cloud" is our new cloud service infrastructure concept that aims at the achievement of a human and earth friendly information society. In "C&C Cloud", a new additional value is created by making the consolidated data of each different field cooperate organically and offering mobile cloud service that shares information through various terminals in real time.
For such forthcoming cloud era, communications must become richer, more reliable, and more responsive, which enable any users to make innovations. This talk reviews the ICT evolution in computer, wireless, and optical network technologies, and then provides a new direction of ICT evolution (symbiosis, dependable, and ecology) for the future. We will describe one key factor in this direction, software-definable feature, which enables a virtualized, dynamic, and agile network consolidating packet, optical and wireless networks.
back to program ^ |
|
Application Initiated Bandwidth Guaranteed Services in Optical Packet and Circuit Integrated Networks |
Kenji Fujikawa, Takaya Miyazawa, NiCT |
|
We have been developing optical packet and circuit integrated networks, which can provide not only best-effort services by optical packet-switching but also QoS-guaranteed services by optical circuit-switching on the same fiber (WDM) infrastructure [1][2]. Optical circuit-switching method occupies an end-to-end bandwidth, which is often called optical path or lightpath, in order to provide high-quality services. The networks separate the wavelength bandwidth into packet- and path-resources, and dynamically move the boundary between the two kinds of resources. Besides, the networks transfer path control messages (e.g. signaling, routing, etc) on optical packet-switched links, and therefore can unify the control interfaces of both switching methods. We developed a prototype of optical packet and circuit integrated node, and constructed an experimental network equipping the node. On the other hand, we proposed and implemented a method that extends the socket API for optical circuit-switching, which assigns an optical path to a L4 connection [3]. The method enables end users to use end-to-end optical paths. Our optical integrated networks can apply the method to provide application initiated bandwidth guaranteed services.
In this talk, we install and verify the method in [3] in our experimental optical integrated network. Figure 1 shows our experimental setup for application initiated lightpath establishment/release. This talk focuses on communications between User-1 and User-3. Now we can select two video contents of which icons are displayed on the window of User-1’s PC as described on the left side of Fig. 1. In this experiment, User-1 establishes two lightpaths to User-3 via the optical integrated node. The bit rate per lightpath is 1Gbps. When we click the icon of Video-1, the socket API in User-1’s PC automatically sends the signaling message on optical packet-switched links. We verified that the lightpath of λ1 was successfully established between User-1 and User-3, and the Video-1 was transferred and displayed on the window of User-3’s PC. Simultaneously, when we click the Video-2 icon, another lightpath (i.e. λ2) was successfully established in the same way. The spectral analyzer displayed two peaks for the optical path signals. The video transmissions on the two lightpaths did not have any adverse effects on other path and packet data transmissions. Note that the socket API can also handle the application initiated lightpath release. When we close the windows for videos, the socket API in User-1’s PC automatically sends the releasing signaling message on optical packet-switched links. We verified that the network successfully released the lightpaths and the video transmissions are halted.
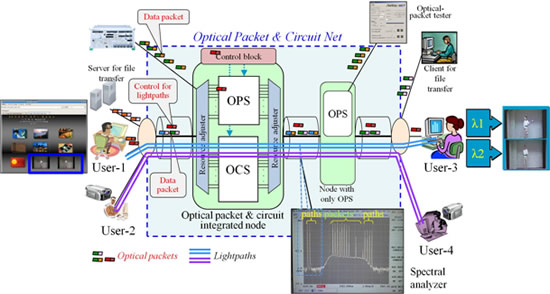
Fig. 1 Experimental setup for application initiated lightpath establishment/release.
References:
[1] H. Furukawa, et al., ECOC2010, We.8.A.4, September 2010.
[2] T. Miyazawa, et al., iPOP2011, 3-3, Kawasaki, JAPAN, June 2011.
[3] K. Fujikawa, et al., iPOP2010, 5-2, Tokyo, JAPAN, June 2010.
back to program ^ |
Break & Exhibits
10:30 am – 11:00 am |
|
What is next with MPLS? Considerations beyond MPLS-TP |
Azhar Sayeed, Cisco Systems |
|
back to program ^ |
|
The Software Driven Network |
Thomas Nadeau, CAT |
|
As service delivery moves from a model in which services and applications move from being offered locally, to those being offered in some form of cloud services, many challenges become apparent. In particular, how does the network operator orchestrate the provisioning or re-provisioning of their network elements such as routers, switches, servers, disk storage, firewalls or gateways? Or worse, as each of these elements becomes virtualized the fluid movement, close integration and tight coordination is critical to the operator’s success (and profitability). This presentation discusses how one solution to this problem might be to enable the applications to control, at least to some degree, some network resources. As one part of available solutions, we will discuss Open Flow, a protocol that allows for applications to remotely control routers and switches. We also discuss a new working group being proposed at the IETF called SDN, which aims to solve this and a larger portion of problem.
back to program ^ |
|
Applying MPLS to "Internet of Things (IoT)": A Look at the 6LoWPAN Case |
Wassim Haddad, Joel Halpern, Samita Chakrabarti, Ericsson |
|
“Internet of Things” is a rapidly emerging paradigm, which in essence, introduces a new type of Internet endpoint. In fact, in the IoT world, even a tiny device with low processing and battery power, small memory and limited networking and service capabilities can become an endpoint. But perhaps the most striking difference with the current market trends (e.g., smartphone, tablets, laptops, etc) is that these tiny devices are expected to spend most of their lifetimes in hibernation mode!
Nevertheless, IoT devices are assigned critical tasks that consist mainly on sensing different elements/factors in their immediate surroundings. They can be deployed in large numbers and cover vast geographic areas. Moreover, they are expected to discover and self-configure key networking parameters that would grant them membership of a specific area and enable them to answer queries sent by local and remote devices at anytime. In some scenarios, the number of responses can significantly increase which in turn, may increase the burden on the routing infrastructure that is also made of constrained devices.
Still an ongoing work in the IETF, 6lowpan working group is introducing optimizations to IPv6 neighbor discovery protocol in terms of addressing mechanisms and duplicate address detection in order to better cope with the above constraints and limitations. In addition, stateless compression protocols are also being designed in the same working group. Therefore, we assume that 6lowpan is implemented on all devices.
In this talk, we investigate the role and impact of using MPLS in a routing infrastructure that is made of constrained routers, in order to minimize data packets size and enable on-demand traffic engineering. In our scheme, a limited number of querying nodes spread within a particular geographic area send queries to one or multiple sensors using a specific combination of short MAC addresses and labels depending on the QoS that is needed at that particular time. While the average bandwidth for sensor networks is very low, events can cause surges. For example, if there is a sudden problem on a bridge, or a sudden weather alarm in a particular zone, a large number of sensors will have to report immediately, and those reports may need to be received with high confidence. These events are the main drivers for rapid bandwidth acquisition and changing prioritization. We show how the combination of short MAC addresses and labels can address the QoS requirements without additional signaling messages and remove the need for carrying IPv6 header in data packets.
back to program ^ |
|
IPv6 strategies in IP/MPLS Networks |
Rajiv Asati, Cisco Systems |
|
More and more network operators are (on the verge of) rolling out IPv6 either internally or externally or both, as they capitalize on (or/and recover from) IPv4 address shortage. Thankfully, they can leverage MPLS, which may already exist in their networks, for external IPv6 deployments accordingly. In fact, few operators have been offering IPv6 offering over their MPLS network. However, if an operator desires moving to IPv6 only network, then it will have to carefully evaluate the IPv6 insertion, if they provide MPLS based services or use MPLS capabilities such as FRR. This talk will focus on debunking IPv6-only MPLS network, share the latest IETF efforts for MPLSv6 realization and explain MPLS usage for CGN/LSN capabilities.
back to program ^ |
|
Future Service Adaptive Access/Aggregation Network Architecture |
Hiroki Ikeda, Hitachi, Hidetoshi Takeshita,
Satoru Okamoto, Naoaki Yamanaka, Keio University |
|
1. Background
Recently, a multi-protocol label switching transport profile (MPLS-TP) has emerged as transport technology alternative to SDH and ATM. Access and metro networks occupy major part of the networks. So, carriers require to reducing CapEx and power consumption by simplified network structure. To simplify the network structure, an aggregation network is introduced to aggregate user traffics and/or service networks.
2. Proposal for future network architecture
We propose service adaptive access/aggregation network architecture which unifies various kinds of service networks into single access/aggregation network. Proposed access/aggregation network unifies leased line networks, micro data center networks, Internet networks, and mobile backhaul networks, etc. To simplify the network structure, proposed network unifies various kinds of service networks, realizes long reach transmission and accommodation of large number of users. Some of the services, for example a leased line service, require high reliable transmission and various kinds of QoS. To realize these requirements, we propose programmable OLT/ONU technology and utilization of MPLS-TP. MPLS-TP has already emerged in core network. So MPLS-TP can control through access network to core network by proposed network. Therefore, end to end high reliability and multi QoS transmission is realized.
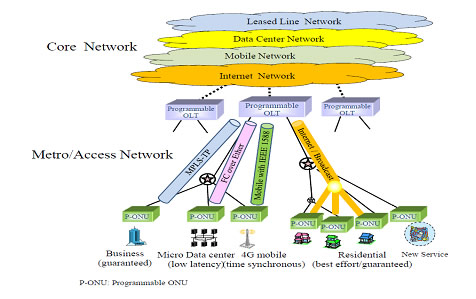
back to program ^ |
Lunch & Exhibits
12:30 – 1:30 pm |
|
Multi-Level Network Management Advancement from R&D to Production Network |
Kenichi Ogaki, Masanori Miyazawa, Tomohiro Otani, KDDI R&D |
|
As the progress in networking technologies, telecom carries have been had to deal with multiple technologies, layers, regions and vendors even in a single network. It turns out that high skills to manage such network are required for operators and it takes long time to provision a new circuit or recover a fault. Consequently, QoS and QoE of services are decreased and OPEX are increasing to solve these issues. In terms of current development style of Operations Support Systems (OSS), existing OSS need to be modified every time when a new service or network equipment is installed. This modification sometimes costs much and usually affects CAPEX.
To tackle these issues, we have been working to achieve multi-level network management architecture which is capable of handling multiple technologies, layers, regions and vendors especially in IP/MPLS/Optical network [1,2]. This architecture allows us to collect resource information and exchange them among OSS by using standardized API, such as SNMP and TMF MTOSI (Multi-Technology Operations System Interface), and those information is modeled based on a network structure with unified TMF SID (Shared Information Data) modeling. It also achieves a real-time fault analysis which locates a root cause and affected customers by using the hierarchical modeling of a network as a proof-of-concept R&D activity. Subsequently, this function was embodied as a real-time fault analysis system in our production MPLS network, called SPIDER, and is currently operating.
In this presentation, we are focusing on three aspects. Firstly, we talk about issues of current network management and development style as described above, and our operators’ requirements for OSS in those function and performance. Secondly, to address these challenges, we describe our proposed multi-level network management architecture which includes a unified resource management, interworking mechanism among management systems, a fault analysis mechanism and the hierarchical modeling. Finally, we show the real-life implementation based on our architecture, SPIDER, which enables fault analyzes for our IP-VPN, Internet access and CS(Circuit Switched)-IP services to handle a large-scale failure in our production MPLS network. Also, lessons learned in this deployment and future works are discussed.
We believe this talk will be helpful of our networking technology to be more solid than ever before.
[1] K. Ogaki, et al., “Prototype Demonstration of Integrating MPLS/GMPLS Network Operation and Management System,” OFC/NFOEC ’06, JThB92. [2] M. Miyazawa and T. Otani, “Real-time root Cause Analysis in OSS for a Multi-layer and Multi-domain Network using a Hierarchical Circuit Model and Scanning Algorithm,” IFIP/IEEE IM ’09, pp. 141-144.
back to program ^ |
|
Visibility into the Dynamics of Evolving IP/MPLS Networks with Route Analytics |
Cengiz Aleattinoglu, Packet Design |
|
The increasing move towards cloud-based infrastructure and services, smart grids, and 4G mobile networks and the reality of IPv4 depletion is causing many IP/MPLS networks to undergo significant evolutions. One thing seems to be a constant—growing IP-layer complexity. This session will focus on how route analytics technology is assisting in achieving and operation specializing these evolving IP/MPLS network environments.
back to program ^ |
|
Mate Deployment for MPLS Network: A Case Study |
Guilherme Tuche, Cariden Technologies |
|
Abstract not yet available.
back to program ^ |
|
LFA in LDP Network |
Fengman XU, WANDL |
|
Abstract not yet available.
back to program ^ |
|
|
|
|
|
|
|
|
