| |
|
Sunday, October 28
TUTORIALS |
|
Tutorial 1: MPLS in Mobile Backhaul Evolution - 4G and beyond |
David sinicrope, Ericsson, Broadband Forum |
|
Long Term Evolution (LTE) data capabilities and smart mobile devices are together providing an amazing range of new services to consumers. These new services will continue generating a bandwidth explosion beyond what is sustainable today. At the same time, spectrum efficiency is critical to making the most of available mobile spectrum. One aspect developing is spreading spectrum over a greater number of smaller cell sites to increase spectrum efficiency and still provide greater bandwidth for evolving services. A challenge of this new model is providing backhaul and aggregation for the higher bandwidth services over the greater number of smaller cell sites. RAN backhaul networks which have traditionally dealt with low capacity data and have been voice centric, now need a smooth migration path to handle the advanced services with higher bandwidth over more equipment.
This tutorial will examine the principal drivers for IP/MPLS backhaul transport infrastructure that accommodates the scaling and latency needs of these evolving LTE mobile networks. Key challenges, options, benefits and tradeoffs of architectures supported with IP VPNs and L2VPN and native Ethernet are explored, along with several deployment scenarios. Details on key aspects of the architecture such as reliability and timing, and its evolution which includes small cells support will be highlighted. Key existing and emerging industry standards/agreements are referenced.
Tutorial Outline:
• Business Drivers
• Ethernet and IP VPN Backhaul Architecture
• Timing and Synchronization
• QoS
• Resiliency, Protection and Performance
• IPv6 Considerations
• Energy Efficiency
• Relationship to MEF 22.1 Mobile Backhaul
• Deployment Examples
• Broadband Forum Mobile Backhaul Workplan
• Summary
back to tutorials ^
|
|
Tutorial 2: SDN: Software Defined/Driven Networks |
Kireeti kompella, Juniper Networks |
|
Software Defined Networks (SDN) is still in its infancy, yet there are already many definitions of SDN, many underlying concepts, and a wide variety of problems SDN is purported to solve. This tutorial brings order and focus to the notion of SDN. It surveys some of the definitions of SDN, some of the underlying concepts and some of the problems to be solved by SDN. It then suggests a unifying definition. The tutorial then switches gears and looks at some implementation techniques for SDN. It compares SDN with routing protocols, routing APIs and SDKs, management systems and orchestration "stacks". Finally, the tutorial concludes by showing how all of the above contribute to SDN.
back to tutorials ^ |
|
Tutorial 3: Mobile Cloud |
Paul Polakos, Peter Bosch, Cisco Systems |
|
As mobile networks evolve and the number of subscribers, handsets, and tablets, increase, the need to manage subscribers and assign various levels of policy implies there is a huge requirement on compute and storage. Service providers are deploying Data Centers to address these requirements. Machine-to-Machine communications only increase these requirements more than 20x.
Not only do the Service Providers needs to build large compute and storage capability but they also need to evolve the network andprovision it on the fly to large changes in demand. It is not an easy task to provision and re-provision vlans, vpns and connectivity with demand. Network Orchestration plays a key role in provisioning and dimensioning the network to make the cloud elastic that grows and shrinks with demand.
back to tutorials ^ |
 |
|
|
|
Monday, October 29
TECHNICAL SESSIONS |
|
Opening Speech: NTT Communications' Perspective on Packet Transport Networks and SDN |
Yukio Ito, NTT Communications |
|
NTT Communications has already deployed packet transport networks by using router-based L2-MPLS and MPLS-TP based aggregation network which is using Decoupled Control/Data architecture with reinforced OAM and fail-over functionality. Through its operation, we confirmed that high avilability and effectiveness of decoupled Control/Data architecture contributed to the network operation efficiency. For the next step, we are planning to introduce PTN in order to intergrate the backbone for each service. Additionally, for network simplicity through layer intergration, we wish to introduce OXC on Optical layer, and SDN for operation intergration facilitating inter DC connectivity.
back to program ^ |
|
Pervasive Virtualization |
Daniel Awduche, Verizon |
|
Pervasive virtualization captures the notion of end-to-end virtualization where end-systems (including user devices and servers), the intervening network, and ancillary resources (including cloud service elements) are all virtualized. Specifically, it entails virtualization of all resources along a specific service path. From an end-user¹s standpoint, pervasive virtualization shifts the economic paradigm from a preponderantly fixed cost model to a variable cost utility model where the user pays for services as needed. From the point of view of service providers, pervasive virtualization unleashes the benefits of joint-production where multiple instances of different types of services are offered to various clients using a common set of network and cloud resources; leveraging economies of scale and scope, as well as statistical multiplexing. This presentation offers some perspectives on pervasive virtualization.
back to program ^ |
|
Keynote Speech |
Vinton CERf, Google |
|
Although the Internet was designed in 1973 and put into operation in 1983, a great deal has happened to communications technology, not the least being mobility and increased data rates as well as new switching methods. MPLS is one of the newer ones but there are others emerging, especially the OpenFlow design. We are also pushing the envelope on other parameters such as disruption and delay tolerance. The Mars Science Lander is one of several spacecraft using some new ideas in networking, made feasible by changing economics of memory size and processor speeds. We have not made much use of broadcast radio, multipath and other phenomena and should be pursuing these as well.
back to program ^ |
Break & Exhibits
10:30 am – 11:00 am |
|
Scalability Considerations for Cloud Computing Service (Invited Talk) |
Yakov Rekhter, Juniper Networks |
|
In this talk we examine state management associated with Cloud Computing Service, and look at possible mechanisms for managing this state in an environment where scalability and cost considerations play a critical role in the choice of the mechanisms.
back to program ^ |
|
MPLS and the Data Center |
Adrian Farrel, Old Dog Consulting |
|
It is often said that MPLS has no place in the data center. But the MPLS data plane is exceptionally powerful for a very low overhead. This presentation looks at how the MPLS data plane can provide both the flexibility and high level of function needed in a modern data center, and at the same time, the encapsulation and forwarding paradigm is very simple meaning that MPLS-enabled data center devices can be manufactured at low prices. Additionally, the versatile control planes available with MPLS can be cherry-picked to provide scalable and highly dynamic solutions to the management and operations challenges of large and dynamic data centers. Furthermore, use of MPLS within the data center of can be leveraged when connecting multiple data center sites.
back to program ^ |
|
Will MPLS Evolve to an Omnipresent Cloud Infrastructure? |
Loa Andersson, MPLS WG Co-Chair and Ericsson |
|
This talk explores various scenarios whereby MPLS could assume a broader role in cloud infrastructure; one beyond that of simple WAN interconnect. This will look at two areas, the first is enhanced services in the WAN for access to clouds and cloud interconnect. The second will focus on broadening the scope of MPLS connectivity. During the course of this exploration various scenarios with respect to how close to the edge MPLS is extended will be evaluated, along with the scaling impacts on the dataplane, and the control plane. Potentially complementary technologies that could mitigate some of the challenges will be explored as well as the interworking implications with the existing MPLS control plane.
back to program ^ |
|
Network Virtualization for Cloud Infrastructure |
Marc Lasserre, Alcatel-Lucent |
|
Evolving the existing data center environment to meet the demands of ubiquitous cloud computing is becoming an increasingly important focus for service providers and equipment vendors alike. This involves increasing scale, and supporting virtualization to allow hundreds of thousands of virtual servers belonging to thousands of tenants providing a multitude of reliable services in a data center. This presentation will look at the requirements and the evolving architectures for massively scalable data center virtual private networks, and how these are emerging from the differing perspectives of players in this space (vendors, traditional telecom service providers, and incumbent data center operators). We will also look at how this is driving new standardization efforts, for example in the IETF.
back to program ^ |
Lunch & Exhibits
12:30 – 2:00 pm |
|
Carrier Use Cases and Application Interfaces for Software Driven Networks |
Dave McDysan, Verizon
|
|
MPLS-based networks have been highly successful in the infrastructure and L2/L3 VPN services of carriers. However, an increasing industry focus is on applications of software and storage in devices as well as in the network to meet the rapidly evolving needs of enterprises and consumers. The presentation will summarize carrier motivations for looking at alternative approaches and how these could best interwork with the large set of deployed MPLS technology to meet these needs. A focus of the talk will be on the abstraction of higher level application interfaces and semantics needed to support these user needs. Experiences and lessons learned from implementing trials using OpenFlow, application level APIs and software driven forwarding will be reported. Finally, some important attributes of application interfaces to MPLS and software defined networks will be proposed.
back to program ^ |
|
SDN in Backbone Traffic Engineering |
Edward Crabbe, Google; RavI Torvi, Sudharsana Venkat, Juniper Neworks |
|
Google is one of the few companies actively incorporating SDN into mission critical networks. In this talk, I'll describe how Google is making use of SDN in our WAN environments to increase network ROI while simultaneously improving manageability and reliability, before moving on to discuss a vision for a potential PCEP and MPLS-TE based software defined network.
back to program ^ |
|
New SDN Architectures for Service Providers |
David Meyer, Cisco Systems
|
|
In this talk we outline a new multi-layer programmability model for service providers. The model is novel in that is comprised of programmability at every level in the protocol stack and incorporates multi-scale feedback between the network and applications with the goal of providing novel opportunities for application writers. In particular, the model is comprised of three main components: what has traditionally been called SDN for control and data plane operations, orchestration to provide "network programming" (contrast element programming), and Big Data engines to provide analytics and feedback. In short, this new model is built on three pilars: The Network, Policy, and Analytics, and is built to optimize service provider networks.
back to program ^ |
|
How Does SDN Impact on an MPLS Network? |
Adrian Farrel, Old Dog Consulting
|
|
ISoftware Defined Networks or Software Driven Networks (SDNs) have attracted a very great deal of interest with enthusiastic presentations at conferences and in marketing forums. However, it has been hard to reconcile a number of different views of what exists behind the SDN acronym and how it relates to real networks. This presentation will examine the applicability of SDN to MPLS networks and will highlight the benefits and inadequacies of existing SDN technologies before explaining which components of the SDN architecture could be worked on for standardization in conjunction with MPLS, and which need to be left to the industry to develop and capitalize upon.
back to program ^ |
Break & Exhibits
3:30 pm– 4:00 pm |
|
Characterizing Stability in Carrier Class MPLS/Ethernet Networks
|
Tom Wilkes, Lawrence Jones, Roman Krzanowski , Verizon |
|
Modern Carrier Networks are under increased pressure to provide high quality services. High quality services can only be provided if the state of the network is constantly measured and reported in order to ensure high Quality of Experience. In most cases, metrics such as Packet Delay (PD), Packet Delay Variation (PDV), and Packet Loss Ratio (PLR) are used to report the status of network services. However, these metrics fall short of giving a detailed view of how networks are performing. In this presentation, we discuss application of more sophisticated metrics, based on time series and higher statistical moments of the Probability Density Function (PDF) of PDV, to reveal the evolution of network state and behavior over time. These metrics — which include shape metrics, floor, and PDV estimates — capture time patterns of network properties, and can be used to characterize the stability of network services. We discuss the shortcomings of current network metrics, present the proposed approach to the monitoring of network health, and provide real-life examples of the use of the proposed metrics in production MPLS/Carrier Ethernet networks.
back to program ^ |
|
Moving Towards a Service Edge Based Architecture |
Nic Leymann, Deutsche Telekom |
|
Traffic is rapidly growing and more and more service providers are looking into the evolution of their network towards a service edge based model for broadband services. Many ISPs are currently investigating in a move towards a service edge as an universal edge for all services (including single, double and triple play services as well as business and wholesale services).
The presentation will give a detailed view about requirements, architecture as well as migration scenarios from the existing network architecture towards service node at the edge and will cover/answer the following questions:
- Requirements: This will cover service provider requirements as well as benefits of a universal edge providing single, double and triple play services for residential customers and connectivity for business customers. Additional services like mobile backhaul and wholesale services are also covered.
- Service Edge Based Architecture: What are the advantages of a service edge compared with the other models which are widely deployed? How are the network and service requirements fulfilled by the service edge based architecture and what are the advantages compared to the existing network architecture? Detailed description of the new architecture. The features and scalability parameters will be described and an overview of the changes to the existing network architecture being deployed at Deutsche Telekom will be given (including the impact on the Seamless MPLS).
- Integration and Migration: Detailed description of migration and integration scenarios of the service edge into the existing (Seamless MPLS based) architecture
back to program ^ |
|
MPLS-TP Deployment Experiences |
Santiago Alvarez, Cisco Systems |
|
This session discusses recent deployments of MPLS-TP and the lessons learned. The main specifications for forwarding, OAM and protection have recently completed the RFC publication at the IETF. Now, beachhead deployments are focusing on specific use cases and prioritizing some functional aspects and services in their deployments. The design of network protection, resiliency and management will be some of the technical aspects to be discussed in more detail.
back to program ^ |
|
|
|
|
|
|
|
|
Tuesday, October 30
TECHNICAL SESSIONS |
|
An Adaptable Architecture Enabled by SDN |
Dave Ward, Cisco Systems |
|
In his talk Dave will present an adaptable and programmable architecture that is enabled by SDN. The architecture presented will show that SDN is a suite of functionality and multiple protocols when brought together advance the capabilities of development platforms and service orchestration. The presentation will also show how programmatic interfaces provide new services and functionality by augmenting existing network control, management and forwarding state.
back to program ^ |
|
What is Software Driven Versus Defined Networks? |
Thomas Nadeau, Juniper Networks |
|
This presentation first defines software defined networks (ONF style), and then discusses the possibilities of expanding this definition into a superset of possible functionality more akin to a superset of functionality.
Software Defined and Driven Standards and Fora This presentation presents and discusses current efforts in standards and other forums wishing to help provide standard interfaces, protocols and interoperable implementations of software driven/defined networks. The presentation will explain the interplay between standards bodies, as well as discuss the key efforts that are ongoing within each body.
Network Programmability Use Cases As the industry evolves towards software defined (and driven) networks, network programmability moves to the forefront. This presentation describes how network programmability is how network equipment, network services and applications would like to interact, and describes how software driven and defined networks are accellerating workflow optimization and closing the feedback loop between applications and network elements/services.
Software Driven/Defined Networks Debate I propose to moderate a debate with service provider and enterprise panelists to discuss the requirements and opinions of those providers around this evolving technology. Panelists should be chosen from premier service providers with preferably experience in deploying SDNs today, or plans in the near future to deploy them. Also, a mix of providers from telco such as Verizon and AT&T to "modern" service providers such as Google, Facebook, and Rackspace, as well as enterprises such as Bloomberg and Citbank will be solicited to join the panel.
back to program ^ |
|
First Multi-vendor Demonstration of Software-Defined Packet/Optical Transport Networks at iPOP201 (Invited) |
Tomonori Takeda, NTT |
|
This talk will present the first showcase of SDN for transport networks at iPOP 2012 (May 31 to June 1 2012, Keio University, Japan). NTT, KDDI Labs, TOYO, NEC, Keio University, Hitachi and Juniper participated the showcase. The topology consisted of five domains which were managed by different controllers such as OpenFlow controller (OFC) ver1.0, OFC ver1.1 and GMPLS controller.
back to program ^ |
|
Split Architecture as an Answer to the Challenges of the Next Generation Networks |
Elisa Bellagamba, Ericsson; Frank Ruhl,Telstra |
|
Next generation networks are built around MPLS in its various forms as the underlying technology in aggregation and core networks, as it is the only technology which is able to provide the efficiency and scale of packet networks while also meeting transport requirements.
But as traffic growth continues unabated in these MPLS based networks, the biggest challenge operators face is that of efficiently scaling the network.
This presentation analyzes the role played by the control and management plane in addressing the issue of efficient scaling while providing a seamless end to end packet based connectivity and taking advantage of the best transport technology in each part of the network. By doing so, the new concept of Split Architecture based around Software Defined Networking will be presented both from the technical and business perspective and its applicability to a Tier1 network operator will be analyzed.
back to program ^ |
Break & Exhibits
10:30 am – 11:00 am |
|
IP/MPLS friendly Protection and Restoration Mechanisms |
George Swallow, Cisco Systems |
|
In pure transport applications protection and restoration require extremely high predictability and SLA guarantees even during a protection event. When these requirements cannot be met, transport networks drop connections rather than risking degradation of other connections.
In IP/MPLS networks, operators are willing to tolerate a small risk in affecting QoS in order to keep connections up even if it means a small drop in voice quality or slowing down TCP connections.
This talk will explore protection and restoration mechanisms that are well suited to IP/MPLS traffic and applications. While a number of techniques will be explored, the primary focus will be on a novel approach to shared mesh restoration. This approach utilizes RSVP signaling, SLRG awareness, and stateful PCE (Path Computation Element). Each element of the system and their orchestration will be examined.
back to program ^ |
|
Complete Protection for LDP and mLDP: MRT Has a Final Solution |
Alia Atlas, Robert Kebler, Juniper Networks |
|
IP/LDP Fast-Reroute has needed a viable 100% coverage solution for years – but the right trade-offs for operational simplicity with coverage have been hard to find. A novel algorithm, MRT, provides not only unicast alternates, but also can be used for multicast fast-reroute and multicast live-live. This final solution uses a computation-efficient algorithm and LDP labels to provide predictable, easy to troubleshoot protection. Maximally Redundant Trees (MRT) is a new algorithm that allows two link and node-disjoint trees to be simultaneously computed. It has a number of applications that are being standardized in the IETF. First, it provides a guaranteed 100% coverage for IP/LDP fast-reroute, if the link or node failure doesn’t partition the network. Building upon this guarantee, it can be used to provide fast-reroute for Multicast traffic via either PLR replication or the use of alternate-trees. Finally, it can be used for multicast live-live so that 1+1 global protection is provided regardless of network topology. This talk will introduce the concept of MRT, demonstrate its applicability and use-cases, and provide analysis results from modeling the different MRT algorithms on real networks. back to program ^ |
|
Remote LFA – Simple and Effective Routing Resiliency |
Kamran Raza, Clarence Filsfils, Cisco Systems; Stephane Litkowski, Orange; Ning So, Tata |
|
Per-Prefix Loop-Free-Alternate (LFA) [RFC5286] provides a major routing resiliency innovation as it enables simple and scalable sub-50msec protection upon link and node failures in the most frequent topologies encountered in the aggregation part of IP/MPLS networks [draft-ietf-rtgwg-lfa-applicability-06].
Remote-LFA delivers on SP and large Entreprises requirements to extend the LFA benefits to even broader aggregation deployment projects involving topologies such as “ring” and “biased square”.
Remote-LFA provides 100% link and node coverage in these topologies while maintaining all the LFA properties of simplicity, scale, incremental deployment and capacity planning.
This is really a significant improvement for SP’s and large Entreprises as the need for scale and simplicity is key in large aggregation network where the number of nodes and links are typically an order of magnitude larger than in the core.
On the core side, Remote LFA may also provide benefits. We report simulations of 11 SP topologies showing a median coverage of 99% (99% of the destinations benefit from protection) and a simple extension to provide deterministic 100% coverage in any topology. |
|
back to program ^ |
|
Multilayer Network Optimizations |
Mazen Khaddam, Cox |
|
Traffic is increasing at high CAGR while the subscriber base and revenue is increasing at a much more modest rate. There is tremendous pressure to increase network efficiency by lowering the cost per carried bit. This study looks at the role of Over the Top Video on the increasing bandwidth requirements in the Cox network and presents multi-layer optimization techniques that can be used to meet the goals. Results obtained through studies using multilayer network modeling and simulation will be presented that demonstrates how service and resiliency levels can be maintained while reducing the total cost using hybrid IP/MPLS and optical protection, and SRLG optimizations
back to program ^ |
Lunch & Exhibits
12:30 – 2:00 pm |
|
A Framework for Controlling Multitenant Isolation, Connectivity and Reachability in a Hybrid Cloud Environment |
Masum Hasan, MONIQUE MORROW, Mark malyon, lew tucker, Cisco Systems; abdelhadi chari, david fahed, France Telecom- Orange Labs |
|
Multiple enterprises (tenants) consuming resources in a public Cloud shares the physical
infrastructure of one or more DCs out of which the Cloud resources are serviced. Hence
one of the major features that has to be supported in public Cloud DCs is multitenant isolation, which is realized via various DC isolation technologies,such as VLAN or VxLAN. In a hybrid Cloud environment where a publicCloud (more specifically off-premises public Cloud resources acquired by a tenant ) becomes an _extension_ of a tenant intranet or private Cloud, the multitenant isolation capability has to be extended beyond the public Cloud DCs. The multitenant isolation _domain_ has to span end-to-end from the tenant network or on-premises resources via the MAN/WAN and the public Cloud DC networks to tenant off-premises resources. While multitenant isolation isolates one tenant from another (inter-hybrid Cloud isolation), an enterprise may desire controlled connectivity to a hybrid Cloud from another Cloud or network or tenant or select resources. In addition, there may be need for controlling direct reachability of resources within a hybrid Cloud itself (intra-hybrid Cloud). The tenant network may be connected to the public Cloud (DCs) over the Internet or a private IP/MPLS MAN/WAN owned or operated by a service provider, which also may support PPVPN (Provider Provided VPN) service, such as the L3 MPLS VPN. In this work we consider the latter type of network and describe a framework for supporting inter-hybrid Cloud multitenant isolation, inter-hybrid Cloud connectivity and intra-hybrid Cloud reachability. We describe uses cases of deploying VPC (Virtual Private Cloud) in a Hybrid Cloud environment supporting the proposed framework. We also discuss the functional architecture of interfacing the management framework with OpenStack Network manager called the Quantum. |
|
back to program ^ |
|
Cloning your Network in the Cloud: A Virtual Environment for Realistic Network Testing and Design |
Colby Barth, Juniper Networks; Arman Maghbouleh, Cariden |
|
This talk describes the use of virtual environments for the testing, design and modeling of IP/MPLS networks. Operators of these networks understand that testing new protocols, design changes, and/or modeling service introductions can be challenging. Most operators have access to a test lab for such purposes, but it is typically limited in size (due to budget and space limitations) and therefore difficult to test or design to the scale of an operational network. Software simulators are also available but often have to make compromises such as assumptions about routing policy and flow-based load balancing to achieve their desired goals. This leads to network representations that are not very realistic.
Network equipment vendors are now offering cloud-based services that enable operators to create and run networks in a virtual environment. Thesevirtual environments run networks consisting of fully functioning images ofnetwork equipment operating systems, as well as the test equipment you would expect to see in a physical lab. Within a virtual environment, operators can essentially replicate their production network and conduct test and design exercises with a level of scale and realism not otherwise possible.
This talk will describe the architecture and technology behind these virtual networking environments, and discuss their potential uses and benefits. Thetalk will also cover the limitations of cloud-based network modeling and testing to help operators determine their best uses. It will also explore one such system, and its accompanying tools, to describe how it was successfully used to validate a transition to an MPLS optimized network. back to program ^ |
|
Leveraging MPLS in Data Center Architectures |
Luyuan Fang, Cisco Systems; Nabil bitar, Verizon |
|
In this presentation, we discuss the data center architecture, first identify each component in data center networking, including both intra-data center connectivity and inter-data center, and both networking elements and computing elements. We then highlight the important differences comparing networking for data center comparing with traditional networking for service providers supporting enterprise customers, for example, multi-tenancy, scaling demand, mobility, and other characteristics specific to data center environment. The solutions for data center inter and intra connections should leverage the existing technologies wherever apply, such as MPLS L3/L2 VPNs, and traditional IP routing and L2 switching without MPLS, and develop needed. Several efforts in IETF will be referenced.
back to program ^ |
|
Data Center Interconnection over MPLS-TP Transport Network |
Hideki Endo, Masayuki Takase, Kenichi Sakamoto, Yoshihiro Ashi, Akihiko Takasi, Hitachi |
|
1. Background
Network services provided by telecom carriers have become highly diversified. Hitachi has proposed a concept “Any services over MPLS-TP”, which enables the separation of network services and the transport network. The features of the MPLS-TP, such as OAM&P, QoS and Operation by NMS, makes a transport network highly reliable and easily operable. Therefore, a common transport network using MPLS-TP gives not only flexibility for network services but also cost-effectiveness and high availability for transport networks.
The recent expansion of cloud services has meant that users demand more flexibility and reliability in addition to convenience. As a result, DC interconnection is required to virtualize not only a DC internally but also multiple DCs interactively.
2. Requirements of DC interconnection
The DC interconnection to virtualize multiple DCs requires Virtual Machines (VMs) to be deployed on multiple DCs and interconnected. To be more precise:
(1)Interconnecting between VMs regardless physical location of DCs
(2)Supporting millions of VMs
(3)Dynamically guaranteeing QoS between distant DCs
The VPN technology using MPLS-TP enables virtualization of physical DC location for Req. (1). Furthermore, Req. (2) is also satisfied by using the VPN technology, because a VM address can be separated from the transmitting one. Therefore, this presentation focuses on Req. (3).
3. QoS issues and our approaches
(1) Provisioning using OAM function
A provisioning is needed to allocate bandwidth for each VM. Therefore, according to the results of On-demand test by MPLS-TP OAM such as delay and throughput measurement, the maximum throughput should be allocated for each application working on each VM.
(2) QoS for burst traffic
Unexpected jitter can occur because the traffic from DCs may be bursty. Therefore, QoS functions such as shaping per VM and priority control should be deployed optimally in the transport network to guarantee bandwidth or delay.
(3) Dynamic reconfiguration by NMS according to VM moving
QoS parameters should be dynamically configured by NMS to follow VMs which move between DCs. Therefore, it is required to switch connections and dynamically reconfigure those bandwidths.
In this presentation, we will discuss the problems and solutions in detail to show that common transport using MPLS-TP is appropriate for DC interconnection applications.
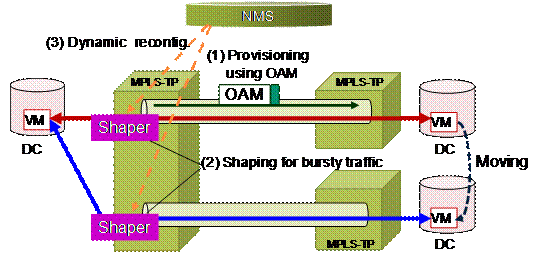
Fig. Separated architecture of Packet Transport and Services
back to program ^ |
|
SDN & Cloud Transport |
Ian Duncan, Ciena |
|
Cloud computing in various forms will benefit from SDN adoption. It is important however to identify focussed opportunities for simplification of engineering & operations, while retaining established and proven techniques and technologies already working well. These are found at the boundary of client-server hierarchical network partitions, which are becoming better defined with the all-pervasive use of virtualization. The full benefit of SDN, and adoption of Openflow in particular, will come from its application to simplified forwarding control that minimizes state installed in the network.
back to program ^ |
Break & Exhibits
3:30 pm – 4:00 pm |
|
Mobility and VPNs |
Azhar Sayeed, Horia Miclea, Cisco Systems |
|
MPLS VPNs have created a network based vpn paradigm that scales very well. Providers have already deployed networks based L3VPNs for business services for more than a decade. Providers have also found solutions to connect remote sites or tunneled VPNs (IPSec, L2TP, GRE) to network based VPNs (RFC2547 style VPNs).
With increasing mobile traffic from Smartphones and tablets the context and the texture of VPNs changes yet again. Now instead of a few devices connecting to remote access gateway via a public network we have 10x or 100x more number of devices that need to connect to the remote access gateways. The mobile providers now face the same challenges to the wire line providers did in providing a vpn service with tunnels (managing large number of tunnels, termination points etc). So it seems we have once again turned a full circle, where we now have a need to solve the tunneled vpn problem for mobile devices and scale the vpns to millions of devices
This presentation defines the problem, states the requirements and suggests an innovative way to solve the connectivity problem for mobile devices by using hierarchical VPNs and optimizing the access network by creating Self Organized VPNs.
back to program ^ |
|
Mobile Backhaul and Wireless Packet Infrastructure |
Peter Bosch, Martin Djernaes, Juniper Networks |
|
Integrating 3g/4g cellular and WiFi today requires WiFi access systems to be tethered to 3g/4g cellular systems. Packets destined to WiFi are first routed to the cellular system, before they are routed by way of overlay tunnels to WiFi. Thus the 3g/4g cellular system provides a global (macro-)mobility anchor, by way of a UMTS GGSN (GPRS gateway) or LTE P-GW (packet gateway), and WiFi is made to look like a 3g/4g cellular system. This implies that the global macro-mobility anchor may become a performance bottleneck, especially considering that WiFi throughput is usually considerably higher relative to 3g/4g throughput and that those anchors are single points of failure, requiring elaborate high-availability techniques to prevent global access failures. We consider this not efficient and not scalable.
We introduce a MobileVPN: a network-based, macro-mobility solution based on IP VPNs that uses MP-BGP and IP/MPLS techniques to manage mobility state at the networking layer instead of as an overlay. When a 3g/4g/WiFi mobile node finds and connects to a new (WiFi) attachment point, a host-prefix (i.e., the host's IP address) is published in the MobileVPN reflecting its new attachment point. By way of BGP processing all relevant routers associated with the MobileVPN, including the mobile node's 3g/4g macro-mobility anchor, are notified of the new attachment point, and the network creates efficient paths to the mobile node. Then, fault tolerance can be provided for de-centrally by regular IP/MPLS techniques without special mobility high-availability techniques. Finally, mobile node IP stacks do not need to be modified to support MobileVPNs.
We present the basic technology of a MobileVPN and describe in detail the mobility procedures, how a MobileVPN compares to existing mobility solutions and how a MobileVPN can be the basis for implementing flexible roaming support among heterogeneous networks (owned and not-owned, cellular and non-cellular access, etc.).
We have built a prototype of a MobileVPN and we reflect on the measured results of this prototype.
Authors: Peter Bosch and Martin Djernaes, Juniper Networks Peter Bosch addressing 3g/4g and WiFi mobility issues (MobileVPN), virtual Evolved Packet Cores for M2M service delivery and CDN-I solutions. Before, Peter co-designed and implemented the world's first UMTS HSDPA systems with MIMO technology, co-designed and implemented the UMTS Base Station Router (BSR), designed and implemented LTE mobility solutions before these were standardized and worked on cloud operating systems and virtual radio access networks. Peter worked at Bell Labs, Alcatel-Lucent before joining Juniper.
Martin Djernaes is senior software engineer at Juniper Networks. Presently he is working on WiFi mobility (MobileVPN) and BGP/MPLS VPN solutions. Before joining Juniper, Martin worked for Cisco Systems in San Jose, CA, as member of technical staff co-designing technologies like NetFlow v9, later named IPFIX by the IETF, Optimized Edge Routing as other BGP quality and security additions. Later, Martin headed the BGP development team at Cisco Systems.
back to program ^ |
|
Energy Efficient Mobile Backhaul |
Konstantinos Samdanis, NEC; Manuel Paul, Deutsche Telekom |
|
The steady rise of power cost in combination with regulatory initiatives and government policies are driving industry and standardization activities towards energy efficiency solutions. Considering mobile networks, the demand for ubiquitous coverage and higher speeds combined with the increasing traffic volumes and flat rate business models raise even further such a need. Current efforts that address energy efficiency, focus is on individual network equipment and protocols mostly at the radio access level considering the user activity, certain infrastructure conditions and pricing issues.
Our proposal aims to bridge such activities towards an energy efficient mobile backhaul solution concentrating on the Broadband Forum (BBF) architecture to benefit from its inherent green attributes, which are based on the converged service principles. The main contribution is to analyze the green insights and potential of the BBF mobile backhaul architecture from the network planning and deployment perspective and specify standardization gaps, limitation and solutions focusing on nodal, transport and Operations, Administration and Maintenance (OAM) requirements.
The objective is to initially overview the fundamental green principles and to explore the energy efficiency external impact of backhaul equipment and protocols on the IP and MPLS based transport. According to such external behavior, we then elaborate how to re-use existing mechanisms, e.g. failure management, and what extensions or modifications are required on certain transport specific protocols, routing/switching and QoS mechanisms. In particular, the primary areas that we consider include:
Network virtualization in network planning, which unifies diverse backhaul technologies (2G, UMTS, HSDPA, LTE) creating a single network infrastructure.
- Nodal requirements in terms of the data and control plane considering lower power states and their external behavior that influence the transport.
- Network based energy conservation analyzing the potential of packet forwarding, traffic shaping as well as routing-transport considering SLAs and the impact of network virtualization in decoupling physical resources from higher layer network protocols.
- OAM and Management including monitoring, controlling and interacting with RAN, failure management and resiliency.
Finally, we introduce forthcoming energy efficient potential topics related to evolving backhaul technologies considering LTE-A.
back to program ^ |
|
|
|
|
Wednesday, October 31
TECHNICAL SESSIONS |
|
Inter cloud network architecture and standardization in Japan |
Naoaki yamanaka, Keio University |
|
|
GICTF is now going to create inter cloud network architecture. And also collaborating with TTC (Japanese Standardization Consortium), they are now under going of standardization. The architecture is combination of cloud resource and network resource. Broker takes care of distributed cloud resources and network resources. This architecture impacts on MPLS-TP, IP VPN and Optical transport.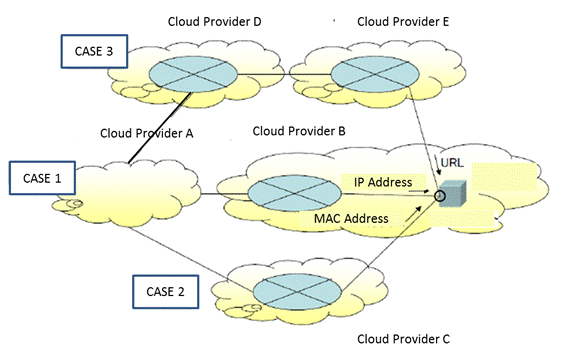
back to program ^ |
|
Inter-cloud Computing Architecture and Interfaces for the Core of Social Infrastructure Systems |
ATsuhiro goto, IIS; Yuichi murata, bo hu, yuichi sudo, NTT |
|
Inter-cloud computing technologies will be one of the “technical and commercial fundamentals” for the secure and reliable cloud computing systems applied to the core of social infrastructures. These technologies will include mechanisms enabling on-demand system reconfiguration and service operation across “autonomous” clouds, operated by different cloud providers, and then providing seamless service deployment for end users even when wide-area disaster occurs. One of the Japanese national R&D projects has been developing the inter-cloud computing technologies for three years and now starts contributing global standardization.
This paper identifies the functional requirements of inter-cloud computing systems by analysing the following use cases: (1) inter-cloud “services” across municipal and central governments, (2) protect lifeline services by accommodating resources among cloud/network providers when disaster or massive breakdown occurs, (3) guarantee end-to-end QoS assurance for totality of server, storage and network across mutually trusted clouds against abrupt increase of the load, and (4) reduce the total power consumption minimizing the number of idle machines by sharing resources with each other.
Then we propose a set of inter-cloud interface specifications based on the above functional requirements. The three reference points specified in this paper are:
- The interface between inter-cloud service controls, which is the interface between cloud service providers
- The interface between inter-cloud service controls and data center operation systems, assuming resource exchange between existing data centers and network carriers
- The interface between the inter-cloud service controls and the network operation systems
The inter-cloud computing technologies are expected to be openly deployed via standardization as well. Global Inter-Cloud Technology Forum (GICTF) promotes these international standardization activities through cooperation with global standards bodies.
The inter-cloud computing interface specifications proposed in this paper will contribute to provide highly reliable cloud services with high-quality service by globally distributed cloud systems cooperation.
back to program ^ |
|
BGP/MPLS IP VPNs as a Data-Center Network Control Plane |
Pedro marques, Contrail Systems |
|
The presentation will focus on the applicability of BGP/MPLS IP VPNs as a control plane solution that provides network virtualization and VM mobility in data-center environements. We will discuss the connectivity requirements, how the BGP/MPLS IP VPN control plane can meet these requirements. The presentation will cover IP unicast, IP multicast and inter-VPN inter-VPN traffic policy support.
The content summarizes the work being developed in the IETF L3VPN WG by a wide range of participant including both network equipment vendors, service providers and large scale data-center operators.
About the author: Pedro Marques is a Software Engineer at Contrail Systems. He is the author of several BGP/MPLS IP VPN standards including "Constrained Route Distribution", "iBGP as PE-CE protocol" and "Flow specification rules". Prior to Contrail, Pedro was the lead Software Engineer working on BGP IP VPNs at Juniper Networks.
back to program ^ |
|
BGP-TE, Application-level Topology Intelligence |
hannes gredler, Juniper Networks |
|
The lack of topological visibility beyond the local IGP area is one of the major shortcomings for applications who need to determine the end-to-end impact of traffic engineering decisions.
Examples: 1. Router-embedded label-switched path calculation implementations have no visibility for paths beyond an area-border router and hence fall back to the hop-by-hop routing paradigm for establishing inter-{area,AS} LSP paths. For constrained LSP setup involving more complex criteria like FRR backup disjointness or SRLG evaluation this means that those constraints are simply ignored by the "invisible" part of the network. IOW the network does not provide the paths that it has been asked for.
2. For off-net traffic-engineering calculations an application server like ALTO or a CDNi redirector needs to understand the physical topology such that it can compute client to content source proximity. This in turn allows to dynamically change the demand matrix for clients accessing their content sources.
3. GMPLS is yet lacking a NNI protocol for exchanging topology data, such e.g. that a OSPF domain can be interworked with an IS-IS domain across AS boundaries.;
This talk is about how to extend the Border Gateway Protocol, such that it can disseminate arbitrary link-state graphs along with their TE information.
Examples in the areas of inter-area TE, ALTO/CDNI based TE and GMPLS, will highlight the importance of this new technology for the MPLS framework of protocols. The talk will be augmented with sample outputs from the JUNOS network operating system implementation demonstarting its applicability to all of the above deployment examples.
back to program ^ |
|
iOverlay – A Multi-Layer Architecture for IP/Optical Integration |
ori gerstel, walid wakim, zafar ali, luyuan fang, clarence filsfils, Cisco Systems |
|
In the context of dynamic traffic patterns and exponential bandwdith growth driven by packet-based multimedia services, we believe that IP/Optical Integration presents a major opportunity for Service Providers to achieve higher service velocity and better monetization of their infrastructure.
We present iOverlay, a Multi-Layer routing architecture, and its application to IP/Optical integration.
Our talk is structures along the following sections:
- Why is this technologically possible in 2012?
- What is “iOverlay” ? How does it differ from a basic overlay or peer model?
- What is the standardization status
- Case-studies
We would propose to allocate most of our time to case-studies such as to leverage and share the experience collected through various ongoing deployment projects with our SP community(*).
Notes: (*) To that extend, as we get closer to the conference, some of our SP colleague may join the presentation to illustrate some of their thought-process and experience.
back to program ^ |
Break & Exhibits
10:30 am – 11:00 am |
|
Load Balancing with Entropy Levels |
Kireeti Kompella, Juniper Networks |
|
The concept of Entropy Labels (ELs) was introduced in the context of "fat pseudowires". ELs have since been generalized to many more MPLS applications. In the process, some significant design changes were made. This talk first presents the drivers for Entropy Labels. It goes over some of the major changes in design and their rationale. The talk then presents the technical details of ELs: how they are recognized and processed by LSRs. The talk includes illustrative examples.
back to program ^ |
|
Addressing Management Challenges of 15 Years of IP/MPLS Innovation |
Cengiz Alaettinoglu, Packet Design |
|
IP/MPLS innovation in the last 15 years has enabled service providers to offer many new services while consolidating network resources. These include layer 3 VPNs, multicast and multicast VPNs, metro ethernet services both point-to-point and broadcast, data center interconnection, LTE backhaul, and optical network transport. These services work both in isolation and also in-concert seamlessly end to end. Building these services required significant control plane protocol work that includes LDP, targeted LDP, RSVP-TE, p2mp RSVP-TE, mLDP, MP-BGP with many address families, GMPLS, and various extensions to IGPs. In addition, these services often require tight SLAs that require configuration of CoS in the network.
This proliferation of protocols introduces a management challenge as they reduce the service provider's visibility on the network's routing and traffic. In this talk, we examine some of these challenges using case studies from IP/MPLS deployments and illustrate how monitoring these protocols along with traffic flows addresses these concerns.
back to program ^ |
|
LDP Operation in Mixed IPv4/IPv6 Networks |
mustapha aissaoui, pranjal dutta, Alcatel-Lucent |
|
The LDP control plane protocol is specified in RFC 5036. It provides the ability of establishing a Hello adjacency and an LDP session between LDP peers using either IPv4 or IPv6. It also provides the ability to exchange many types of FECs: unicast IPv4, unicast IPv6, PW FEC, and multicast LDP (mLDP) P2MP FEC and MP2MP FEC.
One fundamental characteristic of LDP is that the FEC resolution to a link is independent of the type of Hello adjacency running over that link to a peer. In other words, an IPv4 Hello adjacency an associated LDP session allows for the exchange and resolution of not just unicast IPv4 FECs but also unicast IPv6 FECs and any of the above types of FECs. The operator controls which FEC types can be exchanged and resolved between two peers by using the LDP capability advertisement defined in RFC 5561 and by applying inbound filters to the FECs advertised by the peer and which must not be resolved by the node.
This presentation explains how LDP operates in a network where dual-stack IPv4/IPv6 interfaces are used. It provides the details of how the Hello adjacency is established and how it triggers the establishment of the LDP session over both a point-to-point and a broadcast IP interfaces.
The presentation then introduces the new concept of Hello adjacency capability advertisement which allows a fine grained control of which FEC types can be resolved to a link with a dual-stack interface. This is an enhancement to the LDP capability advertisement in RFC 5561 which applies to all sessions and links between LDP peers.
Next, the presentation discusses the requirements stated by operators that the LDP control planes in IPv4 and IPv6 between the same two peers must not share fate. It proposes a mechanism by which the procedures in RFC 5036 are extended to allow separate IPv4 and IPv6 LDP sessions to be established between two LDP peers.
Finally, the presentation discusses a practical use of the LDP LSR-ID field of the LDP identifier. Although RFC 5036 does not specify that the 4-byte LSR-ID be in the format of an IPv4 address or even be routable, many deployments do and derive LSR-ID from a well-known loopback interface address in the system. The main reason for this use is to allow routing protocols, MPLS signaling and OAM protocols to come up using a default routable system address to provide various seamless MPLS based solutions. In an all IPv6 network, a similar capability will be needed to offer the same flexibility. back to program ^ |
|
OpenFlow Advances Networking and Test Requirements |
Jurrie van den Breekel, Spirent |
|
Cloud computing and virtualization are expanding demands on the data center and are pushing the limits of scalability in network switching. For traditional networks to evolve to software-defined networking (SDN), OpenFlow needs to demonstrate interoperability with existing Ethernet protocols in hybrid environments. OpenFlow devices also need to scale and perform across multi-site data centers, virtualized cloud computing and big data networks. This presentation will focus on testing OpenFlow to ensure success of commercial deployment. Areas that will be covered include: OpenFlow testing challenges, testing 100G OpenFlow with Brocade, testing overlay virtualization and an update on various multi-vendor industry interoperability tests.
back to program ^ |
|
Advanced Video Transport System using Precise Time Control and P2MP RSVP-TE |
yuji kamite, yosuke tanaka, kensuke shindome, ICHIRO FUKUDA, NTT Communications |
|
Today there are various needs for video transport services. Some of them require transparent transport of video signals, such as HD-SDI (High Definition-Serial Digital Interface) and DVB-ASI (Digital Video Broadcasting-Asynchronous Serial Interface) for TV broadcasters. In video transport services, it would be needed to deliver circuit connections in a particular time period, to be aligned with the beginning and end time of video program. It is also required to provide video circuit connections on real-time basis, which must follow on-demand request from the customers. In order to meet those requirements, precisely time-controlled connection between video source and receivers is essential because each stream bandwidth becomes huge to support uncompressed HD stream (about 1.5Gbps) and hence efficient resource utilization is much required in carrier’s backbone.
To fulfill such video user’s requirements, we designed network system architecture to adopt P2MP (point-to-multipoint) RSVP-TE (Traffic Engineering) as a key technology. In this system, video transport edge (VTE) node supports packetizing customer’s video signal and establishing end-to-end connection stream using P2MP (Point-to-Multipoint) RSVP-TE LSP. If label switching routers in the backbone network support P2MP RSVP-TE, it is possible to dynamically add or remove receivers by grafting or pruning sub-LSPs using signaling from ingress. Several advanced techniques, such as make-before-break and Fast Reroute (FRR), are fascinating tools for operators to control network resources.
One of the most characteristic features in our system is the strict time-controlling mechanism of RSVP signaling. Because there can be dynamic location change of sender and/or receivers in TV broadcasters for each video program, timing and sequence of RSVP messages must be carefully controlled by the edge nodes. In addition, the edge node supports booking function whereby RSVP signaling is transmitted to create sub-LSPs at accurate time that was pre-ordered from the customer’s request.
This presentation introduces technical system architecture using P2MP RSVP-TE that we developed, which is deployed for our commercial service.
back to program ^ |
Lunch & Exhibits
12:30 – 2:00 pm |
|
Using the PCE to Compute Protection and Recovery Paths for Data Center Services and Applications |
Daniel king, Old Dog Consulting; Huaimo chen, Huawei |
|
The Path Computation Element (PCE) provides path computation functions in support of traffic engineering in Multiprotocol Label Switching (MPLS) and Generalized MPLS (GMPLS) networks. Data center network survivability remains a major concern for service providers, particularly as expanding data center applications such as Private and Public Clouds are increasingly exponentially. A data center link or node failure can significantly impact services and applications within these environments. Therefore it is important to ensure the survivability within data center networks, which consist of a variety of server-layer links providing client-layer and application connectivity, supporting a wide variety of network traffic characteristics with corresponding protection requirements.
A variety of well-known pre-planned protection and post-fault recovery schemes have been developed for MPLS and GMPLS networks. Combined with the PCE, these techniques can be used to provide additional resiliency within the multi-layered data center network. This tutorial presentation outlines how a PCE, and co-operative PCEs, can be used to compute protection paths and restoration services specifically for data centre applications and services, and the varying protection requirements. The presentation outlines the uses cases, extensions and procedures, for various types of client and server layer – including Point-to-Point and Point-to-Multipoint – protection, for both pre-planned and near real-time reactive protection. Finally, the presentation will summarise how new data center technologies like Software Defined Networking (SDN) will drive the development of additional PCE extensions and architecture discussions that will benefit data center survivability.
back to program ^ |
|
Multi-layer Networks and Integration with Non-Packet Technologies |
robert suen, WANDL |
|
The traditional approach in network design is to plan and optimize the network based on the traffic demands, costs, and constraints for a specific single layer. However, a network consists of multiple layers where the server layer provides the transport resources for the client layer carrying traffic demands. Example, a fiber network providing the resources for the IP network demands. Due to various routing and transport technologies and the economies of scale, the network is managed and separated into these two layers, IP and Transport. Thus commonly these layers are designed independently.
The challenge becomes how to design and integrate these multiple network layers to account for constraints in both IP and Transport layers, mapping the IP links to Shared Risk Link Groups on the Transport links, satisfying all IP traffic demands when there is failure in the Transport layer, all while being cost efficient.
In this presentation, we can explore questions and problems encountered by planners: network design using short or long haul links, router dual plane vs. single plane design, and optimizing an IP layer over a fiber optic layer.
For network designs based on link distance, we evaluate the costs for placing router junctions to build short haul links vs. adding optical regeneration to build long haul links. Also, we need to determine the location to place the router and its links. We can construct the two different topologies by assigning appropriate costs to the different equipment types, assign step function costs to distance, and determine the optimal router location and traffic path placement.
For router dual plane vs. single plane design, we evaluate the costs and survivability for each design. The concept of dual plane design nearly guarantees failure protection by routing traffic through the co-plane but the tradeoff is the cost for this redundancy. The approach in single plane design aims to build an optimal cost IP layer that can survive any single fiber cut in the Transport layer and place all traffic demands. We can perform failure simulation in the Transport layer and examine the impact to carry the IP traffic on this single plane vs. the dual plane.
The planning processes for the scenarios described if done manually, is very time consuming and limits the number of optimizations and network designs a planner can make. To quickly design and explore various scenarios, this requires automation that can handle the complexity of dependent multiple layers. The feasibility of using automatic design tools to solve multilayer design issues is demonstrated here using WANDL’s MIND package.
back to program ^ |
|
MPLS in the access: Failure is not an option |
Rajesh rajamani, Spirent |
|
With the proliferation of smart phones and devices and the explosion of traffic, operators are gradually replacing the aging TDM access networks with the more efficient and cost-effective packet networks based on L2/L3 VPN, MPLS-TP or Seamless MPLS. MPLS is also becoming a technology of choice for interconnecting Data Centers.
However, operators are also concerned about the reliability of these MPLS networks. Can link, node or software failures be detected quickly using in-band OAM techniques? Can traffic be rerouted automatically over backup paths without dropped calls or degraded Quality of Experience? It is important to ensure a sub-50 ms switchover post failure—not only for simple point to point MPLS LSPs and pseudowires but also for the more complex multi-home topologies. Finally, it is also important to detect and recover from failures at line-rate data traffic.
Spirent has developed comprehensive support for L2/L3 VPN, Seamless MPLS and MPLS-TP testing by leveraging its IP/MPLS testing platform. Spirent will present test methodologies that will enable NEMs and service providers to easily emulate complex mobile backhaul and inter Data Center connectivity topologies and test MPLS-TP OAM and interoperability with IP/MPLS.
back to program ^ |
|
MPLS Traffic Rate-Limit Control Enhancement |
fengman xu, william copeland, khalid elshatali, luis tomotaki, Verizon |
|
This proposal is for enhanced traffic policing and shaping in an MPLS Layer3 VPN and the backbone carrying MPLS Layer3 VPN traffic.
Background: Current common practice for policing MPLS Layer3 VPNs relies upon:
a) the inherent limit of customer's physical port speed, or
b) the policing or shaping of customer access (ingress/egress) to a sub-rate of the physical connection speed , or
c) flow-based policies based on customer IP packet header information .
Problem: These traffic regulation mechanisms are not enough to prevent a customer from triggering an abnormally high volume of traffic between two VPN locations. For example, an abnormal rate of traffic may be sent from a hub connection to a spoke site. The traffic burst could create traffic congestion on the backbone, especially in extreme cases in which the access port is similar in size to the backbone trunks. Other customer traffic carried in the same busy trunk could be dropped.
Proposed solution: The policing or shaping of traffic bearing MPLS Labels which correspond to specific BGP/MPLS next hops can give the Service Provider much better control of abnormal traffic bursts in the network. For example, such policing could make practical relatively high bandwidth customer access by limiting traffic that is likely to cross the portion of the backbone that is bandwidth limited. To accomplish this, the ingress PE could examine the traffic's destination and limit it based upon the label that matches a particular VPN or PE before forwarding it to the backbone. Much information can also be obtained for model ling purposes by examining traffic with specific labels. The information obtained would be useful for evaluating the impact of any new high speed access requests. In addition, the extended policing/shaping policies could be automatically maintained by a centralized system that has an overall view of network traffic patterns. Enhancements to the current MP-BGP protocol or a different protocol could be used to convey policing policies to clients of such a centralized system.
back to program ^ |
|
Multilayer PCE/PCS |
Stefano Previdi, Cisco Systems |
|
Multilayer Path Computation Server/Element integrates multiple technologies allowing a network infrastructure to deliver different services such as network guidance (e.g.: ALTO) and path computation (e.g.: PCE). A multilayer PCE/PCS server acquires topology, state and resources information from each layer (from optical to application) in order to reconstruct an exhaustive view of the infrastructure and the services running on top of it. The presentation gives an overview of the Multilayer PCE/PCS architecture and functions.
back to program ^ |
|
|
|
|
