|
| Sunday, November2 TUTORIALS |
|||
|
Tutorial 1: Abstraction via Data Models: the Foundation of Modern, SDN-oriented Network |
Kireeti kompella, Juniper Networks |
|
We¹ve come a long way in how we think about networks, how we provision them and how we work with them. Chief among the changes that we¹ve seen is a gradual increase in the conceptual level at which we deal with networks. We started with a CLI or GUI that was very device specific and service provisioning particular to those devices. From there we moved on to more open standards that define interactions between devices and more abstract services specifications. SDN places a greater emphasis on network-wide views; this in turn forces greater abstraction in our approach. Lastly, the need for a programmatic interface to the network and devices again forces us to decouple concepts and implementation. So, how are we to express ideas, concepts, services in an abstract fashion? SNMP had the idea of a uniform definition (in ASN.1), but this was very low-level, and the definitions had minimal structure, and were very hard to modify once made. An API approach offers more control, but is more oriented to syntactic definitions rather than structural relations and semantics. Data models best capture structure and semantics, and do so in a language independent fashion. Data models underlie modern approaches to configuration (netconf, netmod), SDN implementations (Contrail) and SDN-influenced development (Open Daylight and i2rs). This tutorial gives an overview of data models, then goes on to describe how they are used for configuration, for programmability, and in SDN systems. |
|||
|
Tutorial 2: Advanced PCE |
Adrian Farrel,Routing Director, IETF |
|
This tutorial is an update to the tutorial on PCE that was presented by thespeaker at 2008 edition of this conference (http://www.isocore.com/mpls2008/program/abstracts.htm#sun4. It adds material on extensions to PCE, new developments in the architecture, and future applications of PCE. The content includes: - Brief summary and recap on PCE, and where it comes from - Developments in PCE architecture since the early days including Hierarchical PCE - New trends in PCE applicability and architecture including stateful PCE And active PCE - PCE implementation and deployment experience - PCE and its role in SDN and NFV - Application of PCE to new technologies such as Internet of Things and whitespace |
|||
|
Tutorial 3: Open Stack |
Kiran Agrahara Sreenivasa, Brocade |
|
OpenStack is a cloud operating system that controls large pools of computing, storage, and networking resources throughout a datacenter, all managed through a dashboard that gives administrators control while empowering their users to provision resources through a web interface. In this tutorial, after presenting an overview of the OpenStack, we will pursue an actual installation of DevStack which is a documented shell script to build complete OpenStack development environment. Specifically we will demonstrate: - Bringing up OpenStack on a Single machine from scratch(we'll start with a fresh install of 14.04 Ubuntu on a VM) - Provision different classes of networks(Public, Private & Management) - Launch VM's and associate them with the networks above - Optionally launch Brocade Vyatta Virtual Router instances |
|||
|
Tutorial 4: Network Function Virtualization: Reckoning a way Ahead |
al morton, AT&T |
|
There have been many tutorials on NFV in recent years. |
|||
| Monday, November 3 TECHNICAL SESSIONS |
|||
|
Introductio and Opening Remarks |
bijan jabbari, Isocore |
|
|
|||
|
Opening Speech- Software Defined Perimeter (SDP): Framework and General Considerations |
Daniel awduche, Verizon |
|
Software Defined Perimeter (SDP) is a secure overlay dynamic virtual network framework developed by the Cloud Security Alliance (CSA). SDP incorporates a “need-to-know” black network paradigm which mandates device attestation and user authentication as preconditions for visibility and accessibility to privileged services and resources. SDP leverages cloud based controllers and software defined perimeters which can be deployed anywhere in the world. This presentation provides an over of SDP, highlights its value proposition and use-cases, and describes its linkage to SDN and NFV. |
|||
|
Keynote Speech |
NTT Communications |
|
|
|||
|
Service Chaining in Virtualized Networks |
Bruce davie, VMware |
|
Network Virtualization using overlays is now well established as a technique for bringing the operational simplicity of virtualization to networking. As the technology is now being adopted for both cloud and NFV applications, there is increasing focus on the delivery of complete services rather than just connectivity. This requires services to be composed into topologies, or service chaining. Service chains are actually graphs, with packets potentially taking different paths through the graph depending on various attributes such as class of service or user identity. It may also be necessary to pass metadata from one node in the graph to another, to retain information about previous classification decisions, for example. This talk will discuss service chaining use cases and requirements and examine some of the approaches that are emerging to address those requirements. |
|||
Break & Exhibits |
|||
|
MPLS retrospect |
, Juniper Networks |
|
In this presentation we survey major milestones in the MPLS evolution since its inception, and their impact on the current use/deployment of MPLS-based technologies. |
|||
|
Orchestrated Bandwidth-on-Demand for Cloud Services – A Laboratory Demonstration |
Sheryl Woodward, AT&TDouglas Freimuth, IBM |
|
SDN has the potential to revolutionize how networks are architected, built, and operated. However, a greenfield approach is not practical in today's environments that have huge existing network infrastructure. In this talk Dave will present on how I2RS and PCE-P enable adding SDN capabilities that seamlessly cooperate with elements of today's distributed control plane while introducing new services at faster pace and reducing operational costs. |
|||
|
SDN and MPLS for DC |
Luyuan fang, Microsoft |
|
When we have 1,000 new cloud service customers signing up each day, scaling of DC, DCI, and end-to-end cloud networking becomes a whole new game. The following are the key enablers to meet the service on-boarding requirements at scale with improved cost efficiency: simplify operation via technology unification; automate the network fully; own the control plane; drive up resource utilization; and use commodity and unified HW. SDN makes it feasible for us to own the intelligence, remove vendor’s dependency, and realize the full automation. MPLS is an ideal candidate technology for simplifying operation, reducing transport overhead, and providing greater scalability at lower cost. |
|||
|
Architecture and Tradeoffs for Deployment of SDN in Service Provider’s Networks |
Dave mcdysan, Verizon |
|
Software Defined Networks (SDN) covers a range of architectures, methods and standards for separating control processing from forwarding processing at various levels of abstraction. These architectures have different tradeoffs, such as risk/reward, cost/performance, interoperability/feature richness and so forth. This presentation covers taxonomy of the major architectures of interest to service providers and a view into the major tradeoffs encountered. |
|||
Lunch & Exhibits |
|||
|
Overview of NFV Architectural Framework, Requirements, and Use Cases |
andy malis, Huawei |
|
This talk will present a standards-based overview of the ETSI NFV ISG's Architectural Framework, Requirements, and Use Cases documents. It will include the rationale for how the architecture was derived, and its components and interfaces. The presenter was the Rapporteur and primary editor for the ETSI NFV Architectural Framework specification. |
|||
|
Open Stack |
Phil robb, Linux Foundation |
|
Motivation for virtualization of network functions is presented as background. A set of representative use cases from which common requirements are derived are then described. An architecture that places these virtualized network functions in the context of existing physical network deployments (such as IP, MPLS and Ethernet) is then summarized. Finally, challenges and technical problems requiring solution are summarized. |
|||
|
The Roles of Open Daylight, Open Stack and NFV/SFC |
thomas nadeau, Brocade |
|
This presentation presents the state of the industry in these three seemingly different areas, and then explains how when combined, they pose a very real alternative to the state of hardware-based deployments. Network Function Virtualization and Service Function Chaining appear to be the first widely accepted application of SDN and its underlying techniques. Deploying these different components will be discussed within the context of real open source project experience, as well as real product deployments. |
|||
|
Mobile Core Network Transformation to Virtualized Functions & Implications to Resilience and Service Availability |
naseem khan, Verizon |
|
Work on the Network Function Virtualization (NFV) initiative is well underway to redefine core netw ork infrastructure as deployed today. This talk discusses aspects of resilience and service availability in the network virtualization framework The role of the EPC (Evolved Packet Core) elements, architectural aspects, and state management requirements will be explored. Feasibility and benefits of NFV and SDN for expanding M2M services will be also discussed. |
|||
Break & Exhibits |
|||
|
Deploying SDN in Carrier-Grade Data Center |
boris zhang, Telus |
|
From a conventional service provider’s perspective, pursuing emerging service, isolation, security, mobility and integration is the most challenge area but yet a big opportunity to provide value added data center services, there is a desire to develop one integrated carrier-grade solution to guide data center deployment, expansion, migration and new technology application containing SDN/NFV in order to achieve infrastructure optimization, service flexibility and operation automation. The presentation will outline the challenges, opportunities, blue print and a six-dimensional evolution approach to build carrier-grade data center. As an igniter, SDN and NFV plays a key role to transfer traditional architecture to high efficiency functional decoupled integration system, the talk will present that in detail along with the evolution of Infrastructure, network, server/storage, multi-tenancy, service chain and automation to demonstrate the “real word” design considerations of balancing all factors. Map the service selling model to tiered SDN deployment
|
|||
|
Cloud Security |
Priya Natarajan, Juniper Networks |
|
Today’s data centers and cloud face unique security challenges because of virtualization. Juniper’s Firefly virtual security solution is purpose built to provide both (a) security for the cloud and (b) security from the cloud. It protects virtual machines with a range of next generation firewall features. Furthermore it offers connectivity with Junos NAT, Routing and VPN technology. MPLS and VPLS can be used directly on Firefly to allow rapid deployments in large-scale MPLS networks. Firefly is available as VM and it can be deployed easily into SDN solutions like Juniper Contrail SDN Controller for service chaining or VMware NSX. This allows companies to build out secure cloud rapidly. This presentation will cover the security threats, solution as well as key customer deployments and case studies. |
|||
|
DevTest Orchestration for SDN and NFV |
Alex henthorne-iwane, Qualisystems |
|
As SDN and NFV continues to gain traction, service providers are turning their attention from the technologies themselves to their operational considerations. It is becoming increasingly important to plan for useable approaches to ensuring SDN application and NFV service chain functionality now in evaluation and adoption phase of these technologies and create a solid path towards continuous integration of SDN app, API, controller and network device software changes to ensure both high quality and agility of service delivery. In this talk, we will look at the need for SDN and NFV devtest orchestration, how it differs from production orchestration tools, and how it can create the foundation for network DevOps and continuous network certification for heterogeneous network and data center infrastructure. |
|||
| Tuesday, November 4 TECHNICAL SESSIONS |
|||||||||
|
SDN, Segment Routing and the MPLS Architecture |
George SwalloW, Cisco |
|||||||
It has been over 17 years since the formation of the MPLS Work Group and 18 since many of the fundamental tenets of its architecture were conceived. Over that period MPLS has evolved in many directions encompassing Traffic Engineering, L2 VPNs, L3 VPNs, EVPN, Pseudowires, BGP scaling, and MPLS-TP Now Segment Routing with control via SDN is being deployed. Other applications of SDN to MPLS are also being developed. This talk will cover the founding principles of MPLS that have allowed MPLS to evolve and morph in so many ways. It will explore how technology changes in processor speeds and cache sizes, frame size and link speed, and the scalability of IGPs and BGP have enabled ideas that were only dreamed of (if even concieved) in 1996 to be realized. In particular it will explore SDN control of MPLS and Segment Routing.
|
|||||||||
|
MPLS in the Access |
kireeti kompella, Juniper Networks |
|||||||
MPLS started as a core networking technology. Since then, it has moved to the edge, to the metro, to access. In parallel, it is moving to the data center, both inter-DC transport and intra-DC. Given all this, one would have expected MPLS to be widely used all over the network; however, the primary deployment is still in the core and edge. The focus on MPLS in the access has been on scalability (Seamless MPLS), and on the transport nature (MPLS-TP). In this talk, we will offer a new approach to MPLS in the access. First, we will look at a number of characteristics that are relevant to access networks. This will naturally lead in to problems of using MPLS in the access. We will propose solutions to these problems in a holistic way. The proposals include new provisioning paradigms, extensions to protocols and new approaches to access topologies.
|
|||||||||
|
Next Leap for MPLS |
loa andersson, Huawei |
|||||||
Close to two decades ago MPLS was perceived not as cell, but packets technology! That was a moment of convergence, where several technology efforts and requirements from different areas met to form a fruitful whole. This converged whole was much bigger than the parts making them up. Today, we see a similar moment of convergence. MPLS has been developing in an organic fashion for quite some time, but is ready for the next leap. The presentation will discuss how this came about, what areas that has opened up, and the responsibility we have as technology leaders. |
|||||||||
Break & Exhibits |
|||||||||
|
SDN Analytics Bridging Overlay and Underlay Networks |
Cengiz Alaettinoglu, Packet Design |
|||||||
To date, the killer application for software defined networks has been network virtualization. Typical implementations use an overlay network, that is, a set of tunnels over a physical underlay network. The overlay network enables seamless virtual machine migration, elasticity, and interconnection of VMs running in the cloud to the VMs and physical devices running in enterprise data centers. The overlay network typically runs over an IP/MPLS network using a variety of tunneling techniques, such as VxLAN, IP/GRE, MPLS over IP, etc. The controllers may use OpenFlow, BGP, XMPP, layer 2 or 3 VPNs to set up and distribute the overlay tunnel end points. |
|||||||||
|
Stateful PCE in Segment Routing Network Architectures |
||||||||
This presentation discusses the stateful PCE Protocol (PCEP) extensions for traffic engineering using Segment Routing (SR). We provide a detailed description of how stateful PCE can be used to setup, maintain, and delete PCE-initiated SR TE LSP based on SDN application requests. We also describe how PCC-initiated SR TE LSP can be delegated to a stateful PCE for path optimization and control. The presentation suggest how to associate policies with such LSPs for different purposes including traffic steering. Finally, we illustrate a simple approach to centralized SR Traffic Engineering making use of these protocol extensions. |
|||||||||
|
Bridging the Gaps between the Traditional Network and the Software Defined Network |
Huaimo chen, quintin zhao, Huawei; fengman xu Verizon; daniel king, Old Dog Consulting |
|||||||
|
|||||||||
|
FLARE: A platform for the application-driven fusion of SDN and NFV |
Aki nakao, University of Tokyo |
|||||||
We posit that software-defined data plane should enable the fusion of NFV and SDN to provide more flexible and dynamic network services for applications. To that end, we put forth FLARE network node architecture that enables application driven unification of SDN and NFV so that applications utilize programmability in both networking and computational areas more flexibly. FLARE adopts virtualization techniques on top of a combination of multiple kinds of computational resources such as general purpose processors, many core network processors, and GPGPU, etc. We will introduce our recent research activity around FLARE node architecture. |
|||||||||
Lunch & Exhibits |
|||||||||
|
Network Service Chaining for Service Providers |
Nic Leymann, Thomas Beckhaus, Deutsche Telekom AG |
|||||||
|
|||||||||
|
Service Chaining for Carrier NFV |
Homma Shunsuke, Masuda Akeo, NTT Communications |
|||||||
Network Functions Virtualization (NFV) has now been one of the main topics in the literature as a promising architecture for future networks. One important item to be discussed we think is that this notion can be applied to carrier’s core network. Traditionally, most of the telco’s IP-based service functions are running on an all-in-one box called the “edge node”. By separating them from the edge node, and installing them upon servers running in the cloud, we can expect to launch, add or modify services quick and flexible. Moreover, quite an amount of cost saving can be expected by leaving only the packet switching equipment at the edge node. One of the most difficult problems making use NFV in carrier networks is that we should let the user data flows traverse through the network to reach single or multiple service functions that are implemented upon independent servers. The Service Function Chaining (SFC) working group had started in the IETF to tackle this issue; however, we believe we should add several points in order to make the standard to cover requirements for applying service function chaining to carrier's large-scale networks. For example, a control plane mechanism should be considered to preconfigure forwarding policy, rules and tables to a large number of forwarding entities in order to consistently forward the user flows to appropriate service functions. This can be done by distributed autonomous manner just like the protocols used in IP/MPLS such as OSPF, BGP, and RSVP. Or, it may be natural to make use of centralized control such as PCE and SDN. In the presentation, requirements of SFC for carrier NFV regarding the performance, scalability, reliability and operation are addressed both qualitatively and quantitatively. Variations to solve some of the technical issues would be discussed as well. |
|||||||||
|
Service Chaining and Policy |
||||||||
The presentation makes the case for using policy to control service function chaining. We will discuss how IETF SFC components are relevant in such a model, how policies are built and disseminated and standards and/or open source contributions that make these concepts more available. |
|||||||||
|
Dynamic Orchestration and Operation of Chained Network Services |
Sam Aldrin, Charles Perkins, Huawei | |||||||
The deployment and evolution of network virtualization started decades ago. VPN’s are a perfect example of virtual networks. This talk emphasizes the future needs of network virtualization in contrast to present network deployments and how those needs are perceived in terms of large-scale deployments. We primarily deal with the orchestration of network functions (virtual and physical) and how they are operationally managed and administered. The objective of the topic is to present the needs of virtual & physical networks, their functions, and methods to seamlessly transition from existing networks to this new model. Solutions and techniques are presented for dynamic orchestration of end-to-end service chaining and improving its manageability. Preface Details Various orchestration and manageability aspects of NFV and Network Service Chaining (NSC), which are proposed in order to provide streamlined services, are covered in this presentation. As operational complexities and manageability issues increase along with growing network size and capacity, various aspects of NFV and NSC are shown in order to provide solutions for Dynamic Orchestration of seamless service chains |
|||||||||
Break & Exhibits |
|||||||||
|
HA Models and Orchestration for NFV |
Azhar Sayeed, Cisco |
|||||||
| Network Function Virtualization is widely being considered by Service Providers as technology that simplifies network architecture by using general purpose hardware to terminate network functions. However, the success of this is widely dependent on how well the network functions are orchestrated and chained to achieve the desired results. Most of the functions stated as part of ETSI whitepaper are either appliance based, gateway based or embedded into the network hardware today. Any NFV deployment must compete and better the performance and deployment costs of what is done today. This presentation does an analysis of NFV, based on a given deployment model and provides some orchestration rules that allow different and scalable deployment models. It also reviews/discusses HA models that can considered critical for deployment of NFV to better orchestrate and chain capabilities to provide services to flows. | |||||||||
|
Network Function Virtualization (NFV) with OpenContrail |
Bruno Rijsman, Juniper Networks |
|||||||
OpenContrail is an open source platform for network virtualization. In this presentation we describe how Network Function Virtualization (NFV) is implemented in OpenContrail. We describe the high level architecture and demonstrate how the same building blocks for network virtualization in the cloud and for MPLS VPNs in the WAN are re-used to implement NFV and service chaining. We give a brief overview of the control plane and data plane protocols which are used to implement the overlay topology for the service chains. Finally, we discuss the importance of data models, abstraction, and the concept of "SDN as a compiler". |
|||||||||
|
NFV with Open Day Light based Controller |
||||||||
The description for this abstract will be available soon. |
|||||||||
| Wednesday, November 5 TECHNICAL SESSIONS |
|||
|
The GEANT Testbeds Service - Virtual Network Services for European Research and Advanced Applications |
Jerry Sobieski, Nordunet |
|
|
Advanced network research increasingly requires testbeds, deployed at scale, to fully realize and evaluate novel network concepts. Constructing such large scale testbeds - and providing the security, privacy, access to key network switching and forwarding nodes, and control by the user (research team) - pose technical, administrative, and budgetary hurdles that degrade, delay, or completely block advances in network technology, best practices, and/or distributed applications. GEANT, the pan-European research network, is investing in advanced automated service technologies that can create and manage such distributed experimental environments easily and efficiently. The GEANT Testbeds Service (GTS) is a production GEANT capability that provides the user with virtualized network resources such as computational/end system platforms, virtual circuits, and both experimental (OpenFLow) and conventional switching/forwarding elements in a user defined and user controlled distributed environment spanning the European footprint. GTS targets the software defined networking and global network virtualization research communities as they explore these emerging topics, and is working collaboratively with other similar initiatives toward a common global approach to such services. This talk will provide an overview of the GTS service architecture, its current development and deployment status, and the roadmap for the next several years. |
|||
|
SDN/OpenFlow-based Unified Control of 100 Gb/s-Class Core/Metro/Access Optical Networks |
Xiaoyuan Cao, KDDI |
|
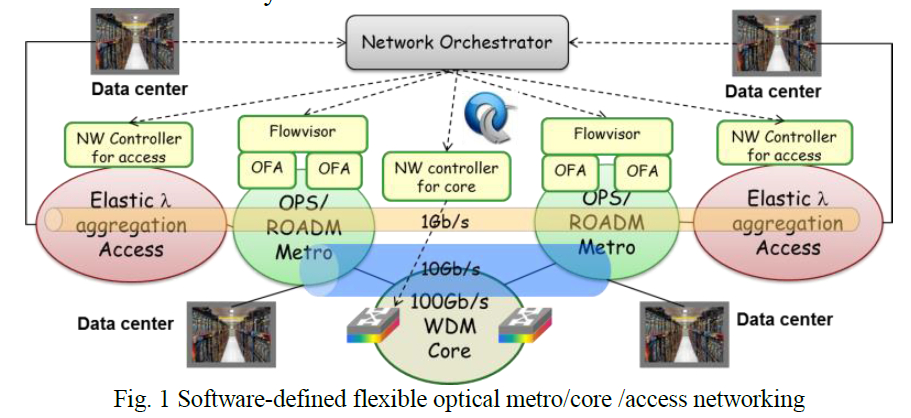
Software-defined networking (SDN) [1] provides a new networking approach to offload the complex control and management functions to a centralized and flexible control plane, with Openflow [1] as a common open interface and communication protocol. Although SDN has been widely researched and partially demonstrated in the traditional IP network, it is yet expected to be extended for the optical networks, i.e. Software-defined optical network (SDON) [2]. SDON will not only benefit from the large optical transport capacity and low power consumption, but also the flexibility and reduced CAPEX/OPEX that SDN brings. On the other hand, with the popularization of cloud computing and datacenter, there’s a growing demand for datacenter/cloud interconnection, as well as the need to dynamically set up high-volume transmission pipe through multiple optical network domains, while SDN technique can be applied for service provisioning and traffic management. In light of this, here we present the interoperability demonstration of SDON across core, metro and access networks. As shown in Fig. 1, the demonstrated SDON comprises of elastic optical access networks, 100 Gb/s optical packet switching (OPS) metro networks [3], 100Gb/s WDM core network, datacenters emulated by traffic generators (Openflow emulators), and together coordinated by a network orchestrator based on Openflow controllers [4]. Optical paths are set up with flexible bandwidth over multiple optical networks based on datacenter requests (1 Gb/s connection across access/metro/core network and 10 Gb/s connection across metro/core network). Multiple optical network technologies are applied in the demonstration, including elastic bandwidth provisioning, OPS based on optical packet and circuit integrated (OPCI) nodes [5], and high-capacity WDM transmission [6]. Each access/metro/core network domain is virtualized and autonomously configured by its own network controller or Openflow agent (OFA), or further sliced by Flowvisor [7] in the case of OPS metro network. Only the virtualized network topology is provided to the network orchestrator in order to improve the scalability. When datacenter sends out a connection request, the network orchestration would perform end-to-end path computation based on the virtual topology, and inform each network domain of the calculation results. Then each access/metro/core network would compute the path and resource allocation within its own domain. After all networks finish configuration, the end-to-end transmission is established successfully.
|
|||
|
OpenFlow-based Waveband Selection Control Interlocked with Dynamic Resource Allocation in an Optical Packet and Circuit Integrated Network |
||
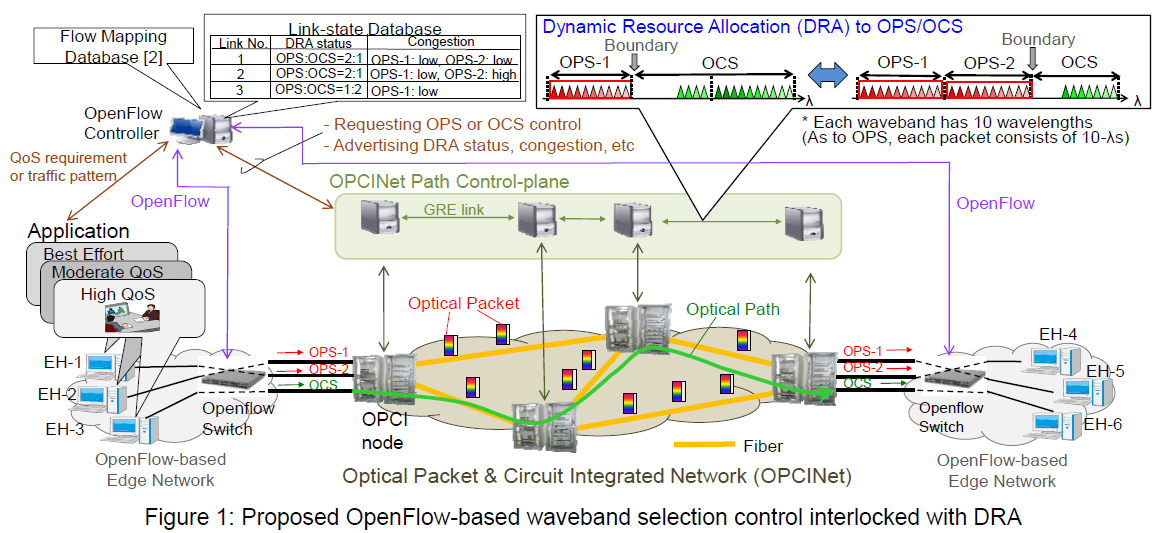
We have been developing an optical packet and circuit integrated network (OPCINet) as a high-speed metro/core network infrastructure [1][2]. In [1], we developed a dynamic resource allocation (DRA) function for a ring-formed OPCINet testbed, which dynamically moves the boundary between the OPS wavelength-resource and OCS one in each fiber link depending on the situation of path usage. Meanwhile, we have proposed architecture for interworking between the OPCINet and OpenFlow-based networks, and experimentally demonstrated a part of the interworking (i.e. interworking between OCS and OpenFlow) by means of the ring-formed OPCINet and an OpenFlow-enabled network-service testbed (RISE) [2]. However, in [2], the flow mapping to associate each flow with an OPCINet control is configured by manual operation in the OpenFlow controller; Furthermore, the DRA executed in the OPCINet is not reflected in the OpenFlow control in each edge network. To realize automatic data transfers from OpenFlow networks to the OPCINet, the OpenFlow controller will be required to analyze each flow’s data, and automatically compute/select one of the wavebands for OPS or a wavelength for OCS in consideration of its quality of service (QoS) requirement or traffic pattern such as bit-rate/burst size as well as link-state (e.g. DRA status and congestion) information in the OPCINet. Then, the OpenFlow switch updates the flow table so that the same flow’s data can be transferred to the output port corresponding to the waveband or the wavelength. We propose OpenFlow-based waveband selection control interlocked with DRA in the OPCINet. Figure 1 illustrates an example of the control, in which we assume a fiber link has 3 wavebands each of which has 10 wavelengths (10Gbps per wavelength). The network dynamically moves the boundary between OPS resource and OCS one in units of waveband depending on the in-use paths in each link [1]: The ratio of number of wavebands in both resources is 2:1 or 1:2 in each link. Each OPCI edge node can get the link-state information in all links inside the OPCINet by a routing protocol for OCS, and regularly advertises it to the OpenFlow controller. OpenFlow controller equips a link-state database in addition to the flow mapping database implemented in [2]. The link-state database has the relationship between links, wavebands (DRA status) and congestion degrees of OPS links. Firstly, the OpenFlow controller analyzes the QoS requirement of each flow’s data coming from end-hosts (EHs): For example, it reads out the ToS octet of IP header, in which end-hosts specify priorities of packets based on applications. Based on the Qos requirement and link-state information, the OpenFlow controller computes and selects a waveband to transfer data of the flow. In this example, a flow from EH-1 prefers low-cost best-effort services (i.e. Class 5 in ITU-T Y.1541 [3]), so one of the bandwidth-shared OPS wavebands is randomly selected, and data of the flow is transferred to the corresponding OPS transponder: In this case, OPS-2 is selected. A flow from EH-2 requires moderate QoS (e.g. Classes 2, 3, 4 in ITU-T Y.1541), so the OPS waveband with the lowest degree of congestion or the highest reachability to the destination node (OPS-1 in this case) is selected, and data of the flow is transferred to the corresponding OPS transponder. A flow from EH-3 requesting high QoS (e.g. guarantee of 10Gbps bit-rate) is exclusively assigned a wavelength for OCS, and data of the flow is transferred to the OCS transponder tuned in the wavelength. Meanwhile, if the OpenFlow controller obtains the information that OPS wavebands experience congestion and sufficient number of wavelengths for OCS is available inside the OPCINet, data of a flow with best-effort or moderate QoS can be temporarily transferred to an OCS link.
References: |
|||
|
Global Optimization of Packet Transport Network based on Logical Plane Switching |
Kenji Fujihira, Hitachi |
|
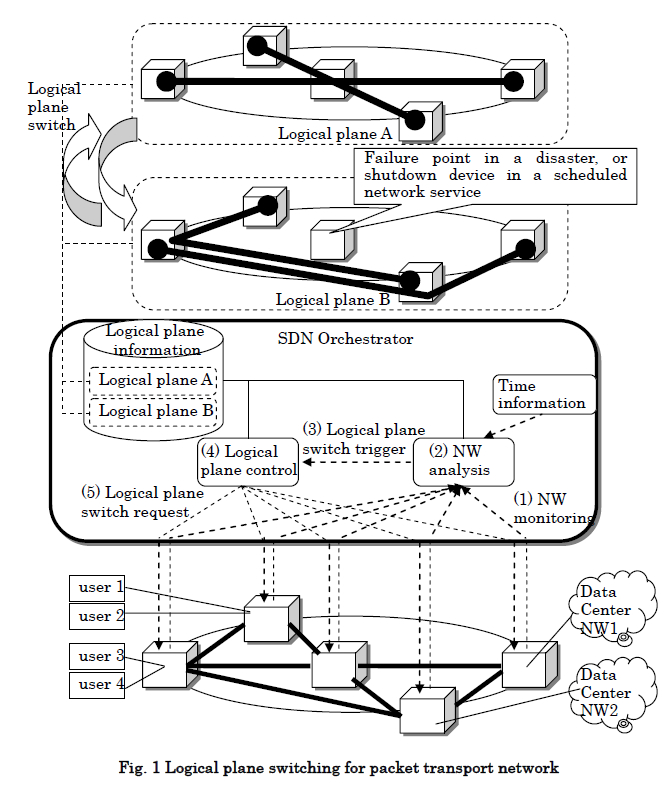
Recently, user demands for network services have been diversified. Especially users expect QoS which enables users to continue using high priority communication services even when the network cannot continue to accommodate all services due to a disaster, and scheduled service which enables users to communicate by paying only for the time and bandwidth they use. Operators’ revenue will increase by providing these attractive services. In order to put these services into practice, operators’ networks need to realize both high reliability to continue services when faults occur, and global optimization to accommodate various traffic for each user and time by efficiently utilizing limited network resources, such as network nodes and links. Previously two techniques, protection switching and rerouting, have been used to change each route. Protection switching realizes high speed switching to protection route registered by the operator in advance, within 50msec when a fault occurs. However, protection switching has issues on inefficiency of network resource usage due to resource allocation of protection routes, and on service disruption when faults occur both on working and protection routes due to a disaster. On the other hand, rerouting is a technique to change a route by re-computing the most appropriate route. However, rerouting has issues on difficulty in utilizing network-wide resource usage efficiently since rerouting is performed for each route, and on difficulty in high speed route change since re-computing is performed after a trigger happens, which may result in service disruptions. We propose packet transport network system where centralized control is performed by SDN orchestrator and it dynamically assigns network resource to globally optimize the resource usage efficiency (Fig. 1). The proposed network system is characterized by its SDN orchestrator which manages multiple logical planes. A logical plane is defined as a group of logical routes and their assigned bandwidth, which operators register in advance. In order to apply the most appropriate logical plane to the network, SDN orchestrator has NW analysis function and logical plane control function. NW analysis function monitors and analyzes network status and selects the most appropriate logical plane. Based on the information of time, node failure and loss of services (1), NW analysis function selects the most appropriate logical plane in terms of bandwidth assurance, connectivity of user service, resource usage, and power consumption (2). On receiving a trigger (3) from NW analysis function, logical plane control function (4) send logical plane switch requests to network nodes (5). When a disaster happens in the network and the loss of services number exceeds pre-configured threshold, SDN orchestrator selects and switches logical plane in a short time, so that high priority services’ communication routes bypass node failure point. In this way, the influence of disaster on high priority services is minimized. As a result, operators can continue providing high priority services by effectively utilizing limited resources. On the other hand, when a operator provides scheduled service, SDN orchestrator applies logical plane to the network so that unused devices (for example, interface cards) can be shutdown for power saving.
|
|||
Break & Exhibits |
|||
|
Privacy and Security in MPLS Networks |
adrian farrel, Juniper Networks |
|
Over the last twelve months the dual concerns of privacy and security have been brought to the consciousness of a high proportion of Internet users. At the same time, network operators have started to focus much more on how they can provide security and privacy for themselves and the data with which they are entrusted. Where once networks were operated on the assumption that the infrastructure components could be trusted and were secure, access lists maintained at the network edges and secure management systems are no longer considered sufficient protection for MPLS networks. This presentation will set out the assumptions of secure infrastructure and trust domains, outline the objectives and requirements for security and privacy, and summarise some of the attack vectors and opportunities for disrupting networks, before looking at how MPLS networks can offer additional security. The speaker will address the following topics: Security in network management is one area of MPLS networking that leverages existing tools and mechanisms with a relatively high level of security. End-to-end payload security can be applied between end systems or just across the MPLS network. It requires the establishment and management of Security Associations and the exchange of keys. |
|||
|
New paradigm for proactive network operation: big-data analytics-based operation and QoE-centric operation |
Kohei Shiomoto, NTT R&D |
|
In this presentation, we will introduce our R&D efforts called "analytics-based operation" and "QoE-centric operation" for proactive network operation. We build inter-disciplinary research framework by combining research fields such as machine learning theory, control-theory, information theory in addition to optimization theory, graph theory, statistical analysis, queuing theory, etc. We figure out the latent mechanisms behind the change of traffic and network status to enhance the quality of network operations by employing control theory, machine-learning theory, and others on data collected for network operation. Traffic data, syslog data, and Twitter data is analyzed for various network operations: traffic-engineering, trouble-shooting, QoE-sentiment analysis. To provide optimal QoE to the end customer, we build a model composed of network layer, application layer, QoE layer, user behavior layer, and business layer, where each layer interacts with each other for user experience improvement. In this context, we expect the NFV/SDN technologies provides the following merits: (1) Implementation of carrier’s operation policy such as proactive operation based on data-driven traffic and QoE management, Traffic pattern is unexpectedly changing, as the way communication networks is used is changing (as we see explosive growth of mobile services, video services, IPTV, SNS, smartphone, tables, etc. and we also see complex network structure composed of ISPs and CDNs, and we also see over-the-top (OTT) players dominate in the value-chain of communication services). Trouble-shooting of communication network is getting complicated as the way the communication network is constructed is changing (we see diversified network elements such as switches, routers, servers, load-balancer, etc. are used to build the communication networks and those network elements are provided by different manufactures). We argue that our R&D efforts for proactive network operation, combining NFV/SDN technologies, will address the issues for the future networks.
|
|||
|
Segmented Ingress Replication - Applying Seamless MPLS Multicast to Ingress Replication |
Jeffrey Zhang, Juniper Networks | |
Use of Ingress Replication to carry multicast traffic of VPN customers over the VPN provider infrastructure has several advantages over using multicast trees/LSPs for carrying this traffic. However, there are also drawbacks of using Ingress Replication for carrying this traffic. In this talk we briefly review the practical benefits of using Ingress Replication for carrying multicast traffic of VPN customers, as well as its drawbacks. We then proceed to describe how these drawbacks could be ameliorated by applying segmentation procedures of Seamless MPLS Multicast. We also describe operations and benefits of mixing segmented and non-segmented Ingress Replication. This presentation will be jointly prepared by AT&T, Cisco and Juniper, but presented by a Juniper speaker. We're also exploring a joint interoperability demo. |
|||
|
Router Bypass Design and Content Peering Dynamics |
David T. kao, Time Warner Cable |
|
Router bypass, also known as router off-load, when architected properly, can be an effective way to reduce the cost of layer 3 network. It allows transit traffic to stay in layer 1 without touching the intermediate layer 3 nodes. In addition to the increase in Capex efficiency, router bypass also reduces traffic impairments such as latency, jitter, and packet loss. The design of router bypass is a challenging task requiring visibility and analysis of both the layer 3 and the layer 1 networks. For a typical service provider backbone network, there can be millions of possible layer 3 topologies with various levels of router bypass implementation, resiliency, and traffic impairment characteristics. Successful design necessitates a multi-layer capable network modeling tool as well as investment in resource and skills to build a multi-layer network model and to formulate an appropriate cost function. Methodology of multi-layer network modeling and router bypass design was covered in a MPLS/SDN 2013 presentation by the authors. In the past, the contents over the Internet were broadly distributed. With the advent of OTT (Over-The-Top) video and the market force behind the OTT contents distribution, the majority of Internet contents now come from a handful of content providers. As the result, the change of peering relationship with a single peer can potentially result in substantial traffic shift in an ISP network. This creates a unique challenge for layer 3 and router bypass design. Due to the traffic shifts from the ever changing peering relationships, an optimal layer 3 design today can be rendered sub-optimal tomorrow. This presentation provides an analytical framework for evaluating layer 3 and router bypass design in the context of content peering dynamics. The methodology, tools, and process to assess the layer 3 design persistency are presented. Analytics results from a real ISP backbone network are provided to illustrate the approach. Guidelines are proposed to assist layer 3 and router bypass design in the face of changing traffic matrix. Common challenges are discussed, and mitigation strategies are proposed.
|
|||
Lunch & Exhibits |
|||
|
SDN/NFV infrastructure and orchestration testing |
Rajesh rajamani, Spirent |
|
Validating routers, switches, data center fabrics and L4-L7 appliances used to require a hardware based solution. However, with the adoption of SDN and NFV, many of these routing functions and L4-L7 appliances are migrating inside a data center and running as VMs on common off the shelf servers. The test functions needed to validate the network functions are also becoming virtualized to run as VMs in COTS servers. The performance predictability and reliability of VNFs and service activation challenges are all barriers to adoption of SDN/NFV. Spirent will present testing methodologies to help ensure the seamless migration to virtual environments and performance/reliability equivalence between virtual and physical environments. The orchestration of applications and policies in SDN/NFV environments also need to be validated and Spirent will also introduce methodologies to perform end to end validation of services, SLAs and orchestration policies. |
|||
|
Software defined WAN technologies for network business innovation Project |
Atsushi Iwata, NEC Corporation |
|
This talk introduces overview of O3 project where 5 companies jointly develop fundamental technologies for achieving Software defined WAN, including Optical/Packet, Mobile/Wireless, Carrier access and Intra/Inter DC transport. WAN consists of different network media, each of which is independently managed by different design, deployment, and operation, and thus is difficult to provide an agile service infrastructure deployment and also difficult to optimize network resource in multi-layer and multi-domain environments. In order to solve this problem, O3 project, therefore, provides object-oriented network controller platform, which can easily handle different network media in a common framework. Using this platform, we have achieved multi-layer network visualization (including topology, traffic and its failure status) for different network media in multi-layer and multi-domain fashion. We have also achieved IP/Optical convergence system to provide multi-layer network resource optimization. Both systems have been evaluated in a testbed system to show its effectiveness of these schemes. |
|||
|
Optimizing Cloud Workload Placement Over a Wide Area Network |
JOhn evans, Cisco |
|
With the deployment of cloud services and Software Defined Networks (SDN), services can now be deployed on-demand, i.e. faster than network and data center resources can be provisioned. Further, with the virtualization of network infrastructure services through Network Function Virtualization (NFV), there are choices as to where each service may be placed. New resource management capabilities are required to keep pace with the speed of service provisioning. In this presentation we show how a centralized controller can be used for optimizing workload placement taking into account the availability of both WAN and data centre resources. We show how such a system can ensure that SLAs can be met whilst also making efficient use of the underlying resources. We present results which demonstrate the efficiency gains that can be achieved with this system in optimizing the use of network and data center resources. |
|||
|
A Case Study of Datacenter Network Design in the age of emerging technologies – requirements, choices, and considerations |
Lei wang, Lime Networks, Christian holmboe, Evry |
|
In last year’s conference MPLS/SDN 2013 we presented challenges in EVRY's existing Data Center network and target architecture which is to be realized in EVRYs extensive transformation program Future Proof. Evry is a mature datacenter and hosting service provider in Nordic region supporting customers across all industry segments, including significant deliveries to the bank; finance sector dating back 50+ years. This means that the company owns and operates generations of solutions and technology platforms. The majority of the implemented services is based on a traditional three-tier network infrastructure composed of access, aggregation and core layers. The current technical platform, organization model and delivery processes are under a major transition to meet the demand for modularization of functionality, verticalisation of value chain deliveries, and dynamic scalability of production. A major activity of the transition is to establish two modern datacenters which bring state-of-art energy and cooling efficiency. Today’s 18 datacenter sites will be consolidated to the new datacenters in the coming years. A RFP project to establish a modernized datacenter network has been carried out in this context. Through this project we have gained an overview of various design alternatives and technology choices supported by vendors today, as well as major trends of development. We would like to present our final design choices and which considerations are behind the choices we made. Our overall goal is to enable a multi-vendor, multi-tenant datacenter spanning legacy, customer dedicated, private cloud and public cloud deliveries. The outline of our topics is as following: The requirement specification to the network design team from the surrounding departments in Evry: Economy of scale invites a horizontal delivery organization across value chains while the shift from technology-focus to business value chain focus triggers a verticalisation of operational responsibility to offer end to end visibility of functions throughout a business value chain. In addition, the more recent shift of focus towards multi-vendor landscape for IT services introduces the need for increased standardization of interfaces and interoperability across domains and delivery models. This includes northbound and southbound as well as east-west bound interfaces. An agile and changeable multi-tenant hosting environment must be tolerant to technological diversity while supporting boundaryless information flow (see TOGAF 9.1) across the aforementioned interfaces. |
|||
|
A Study of SDN-based Control Architecture for Optical Transport Networks employing an SDN Adaptor with GMPLS Signaling |
Shan Gao, Hitomi Yoshimura, Masaki Tanaka, Sota Yoshisa, Takashi Sugihara, Mitsubishi |
|
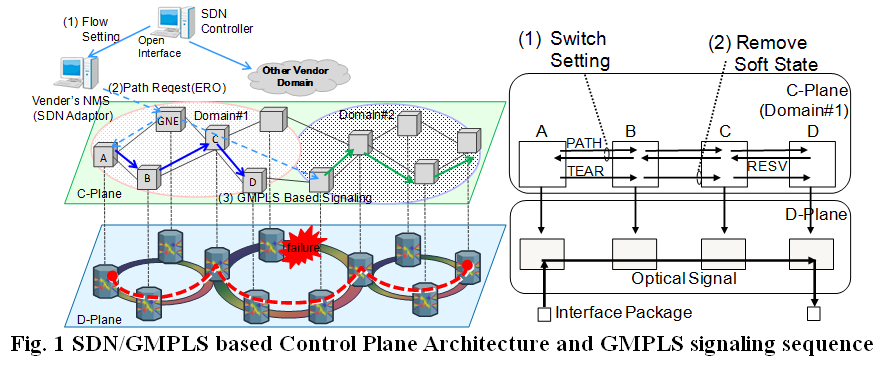
Software Defined Networking (SDN) is a promising approach for unified control across multi-technology networks. Intensive investigations have aimed at moving the SDN concept out from datacenter networks to large scale multi-layer transport networks [1-2]. One of the most effective uses of SDN-based transport network control is integrated multi-layer recovery. However, certain difficulties bar it from practical use. In optical transport networks, vendor-specific attributes such as the fault isolation process, accessibility of wavelength paths and switching time have to be considered during the path provisioning and restoration processes. The attributes should be abstracted so that an SDN controller can uniformly manage multi-vendor/multi-layer networks. Additionally, if multiple failures occur simultaneously due to a disaster, managing a large number of paths will load the controller heavily. We present an improved SDN-based control architecture for end-to-end path provisioning and restoration in large scale optical transport networks, in which an SDN adaptor and SDN controller manage the Network Elements (NEs) as shown in Fig. 1 (left). The following three approaches improve an existing architecture in terms of fault isolation, accessibility of wavelength paths, and switching time. (1) SDN adaptor (2) Moving the control plane from the NEs to an NMS (3) Per-domain Parallel Signaling In the last part of this presentation, we discuss the design and implementation of an SDN adaptor.
[1] Jie Zhang, Hui Yang, Yiming Yu, Xiaobing Niu, Xuefeng Lin, “Which Is More Suitable for the Control over Large Scale Optical Networks, GMPLS or OpenFlow?,” OFC2013, Los Angeles, USA, Mar.2013. |
|||