| |
 |
Sunday, October 25
TUTORIALS |
|
Tutorial 1: MPLS in the Cloud Computing and Data Centers |
Kireeti Kompella, Juniper Networks |
|
This tutorial considers the networking implications and requirements of the "Cloud", and how MPLS can be used in that context. Cloud Computing in all its forms requires:
1) Very very large scale: 10s of thousands of servers, 100s of thousands of Virtual Machines, millions of users;
2) Resilience, both of data and of connectivity;
3) "Virtualization", in many forms:
- Multi-tenancy at the VM level needs isolation and handling of overlapping MAC and IP addresses.
- Inter-Data Center (Inter-DC) communication needs Layer 2 or Layer 3 network virtualization.
- User-to-Cloud communication may need user-level isolation and privacy at Layer 3.
4) Mobility: users may move, apps may move, VMs may move;
5) Elasticity: dramatic changes in resource requirements over the course of an interaction with the Cloud;
6) Orchestration: the ability to quickly and seamlessly commission, expand/contract and finally decommission a session with the Cloud.
We will describe each of points in more detail, and show how MPLS can be used to either satisfy or simplify the requirement. The tutorial will conclude with a brief examination of future topics.
back to tutorials ^ |
|
Tutorial 2: Mobile Packet Core |
Azhar Sayeed, Cisco, AT&T |
|
Mobile IP traffic is dramatically expanding and it is estimated to be nearly four exabytes per month by 2014 -- a 53 fold increase and 128% CAGR from 2009 (Source: Cisco VNI). As operators continue to roll 4G cell sites to support Long Term Evolution (LTE) services, service providers need an end to end integrated transport and mobile packet core architecture from cell site to core. Operators need to have the ability to support 2G, 3G, LTE transport coexistence, legacy and carrier Ethernet transmission, cell site capacity and cost optimizations through fiber rings. Service Providers need to enable IP/MPLS VPN architectural capabilities for LTE transport that would enable Evolved Packet Core (EPC) gateway distribution for supporting caching based internet offload, security gateway integration in the transport for X2 optimization and IP multicast for LTE eMBMS service. This session focuses on the key challenges, requirements and deployment models for such an integrated mobile transport network.
back to tutorials ^ |
|
Tutorial 3: MPLS-TP in Multi-Service Packet Network Deployments |
Broadband Forum Ambassadors, Broadband Forum |
|
MPLS Transport Profile (MPLS-TP) is an emerging set of standards that facilitate the use of MPLS in transport networks, as well as aiming to simplify the Operations and Management of existing packet based architectures. This tutorial offered by the Broadband Forum will explain the applications and use-cases for MPLS-TP in transport and multi-service broadband networks, supporting multiple services such as mobile backhaul, carrier Ethernet, residential wholesale traffic, business services, etc. Technology, business and market drivers for MPLS-TP will be highlighted. An overview of this emerging technology, touching on the OAM characteristics, as well as how the control plane will function and survivability is assured will be discussed.
back to tutorials ^ |
 |
|
|
|
Monday, October 26
TECHNICAL SESSIONS |
|
Opening Speech |
Speaker,
Title, Company |
|
This abstract will be available soon.
back to program ^ |
|
Keynote Speech |
Stuart Elby,
VP, Network Architecture, Verizon |
|
This abstract will be available soon.
back to program ^ |
|
Invited Talk: Scaling Multicast MPLS - Seamless MPLS Multicast |
Yakov Rekhter, Juniper Networks |
|
In this talk we outline a scheme to improve MPLS multicast scalability. This scheme is build upon two key components: P2MP LSP Hierarchy, and P2MP LSP segmentation. The scheme is applicable to a wide variety of services that rely on MPLS multicast.
back to program ^ |
Break & Exhibits
10:30 am – 11:00 am |
|
A Carrier's View on MPLS in Transport: Fairy Tale or Reality? |
Julien Meuric, France Telecom-Orange group |
|
Once upon a time there was MPLS. Before it reached its tenth birthday, this successful technology started to address many use cases and application domains, including transport networks: thus the so-called "MPLS Transport Profile" was born.
While the standardization effort is still on-going in the IETF, the presentation will highlight a carrier's point of view on the MPLS evolution towards transport networks, leveraging the experience of a global scale telecommunication group. As one size never fits all, the talk will try to emphasize the main differences between an incumbent carrier and a 21st- Century service provider, or between a large-scale European network and a reasonablescale emerging country.
Some technical aspects of MPLS will be tackled and put into perspective. For instance, the lacks and extensions of MPLS OAM features will be discussed. The control plane uses will be exposed, considering both the protocol knowledge learnt from IP and MPLS deployments and the GMPLS uses over actual transmission networks. Network management will not be forgotten, including the legacy and the current needs. We will also illustrate how management and control planes can be associated, considering actual examples from operational networks. Putting the light on the historic boundary between packet and transport networks -- which are spanned by the MPLS-TP project -- will hopefully help them to live happily ever after...
back to program ^ |
|
Why MPLS-TP and How? |
Ning So, Nabil Bitar, Steven Gringeri, Verizon |
|
This presentation will focus on drivers for utilizing a GMPLS/MPLS-TP-based network for packet transport from a carrier perspective. It will also illustrate via some potential deployment scenarios the benefits that can be attained and the challenges that need to be addressed. The presentation will also describe a vision for a future transport network and compare it to today’s TDM based transport networks.
back to program ^ |
|
Scenario for Migration of Legacy Networks to a Next-generation WAN by using MPLS-TP |
Masayuki Takase, Takumi Oishi, Kenichi Sakamoto,
Hideki Endo, Yoshihiro Ashi, Akihiko Takase, Hitachi |
|
1. Background
A new packet-transport system based on the “Multi-Protocol Label Switching Transport Profile” (MPLS-TP) has been developed. MPLS-TP is a connection-oriented packet-transport mechanism based on MPLS that provides managed point-to-point connections. As the number of wireless users on 2G and 3G services will continue to increase, it is expected that the next-generation wide-area networks (WANs) will converge not only carrier-grade Ethernet services but also legacy leased-line services by utilizing time division multiplexing (TDM) and asynchronous transfer mode (ATM) technologies. In this presentation, the way to converge legacy services to next-generation WAN based on MPLS-TP technology will be described.
2. Key issues concerning migration
In regard to the migration of legacy leased-line services to a WAN by utilizing MPLS-TP technology, the following two keys issues must be addressed, namely, managing network resources and controlling traffic statically.
2-1. Network-resource management
Each node in a WAN is configured with static paths by a network-management system (NMS). Moreover, the NMS manages the bandwidth of each node and checks whether the required bandwidth can be assigned or not in order to set up a new static path. Guaranteed end-to-end (ETE) paths are provided by this resource management.
2-2. Traffic control
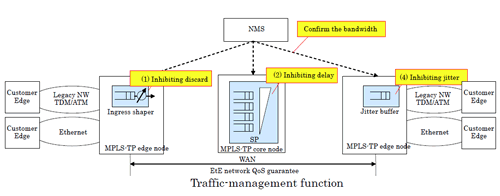
Traffic control aims to inhibit packet loss and to suppress end-end delay and jitter. To achieve these aims, the developed packet-transport system takes the following three approaches.
(1) Incoming-packet shaping
An incoming-packet shaping function is deployed at the ingress WAN edge node. It is used to control the rate of packet transmission and to prevent transmitted packets from overrunning or becoming congested. As a result, legacy-service data will not be discarded by the WAN.
(2) Congestion control
A “strict priority” (SP)-queue function is deployed at the WAN core node. Legacy service data are then queued in a high-priority queue. As a result, delays of legacy data in the WAN are minimized.
(3) Jitter absorption
Since packets have various lengths, legacy-service data get transmission jitter at each node. A jitter buffer that absorbs these jitters is thus deployed at the egress WAN edge node.
3. Summary
A new packet-transport system based on MPLS-TP for next-generation WANs was developed. This system makes it possible to converge carrier-grade Ethernet services and legacy services on the same WAN by using optimally applied QoS functions. It is thus suitable for mobile backhaul.
back to program ^ |
|
MPLS-TP Deployment Scenarios and Design Considerations |
Luyuan Fang, Nabil Bitar, Raymond Zhang, Cisco, Verizon, BT |
|
In this presentation, we will discuss the following:- MPLS-TP: Hype or Reality? - What are the key differences between T-MPLS and MPLS-TP? - What is the relationship between MPLS and MPLS-TP? - MPLS-TP use case study:
- Mobile backhual
- Packet Optical Transport
- Carrier Ethernet Aggregation
- ATM/TDM/SONET/SDH replacement
MPLS-TP network design considerations:
- Interoperability with existing MPLS networks
- The importance of standardized solutions
- Operation impact of technology decisions
- MPLS-TP security, resiliency, and performance
back to program ^ |
Lunch & Exhibits
12:30 – 2:00 pm |
|
Network Enabled Cloud and Service Models |
Monique Morrow, Cisco
|
|
The presenter will discuss the role of the network in developing as a base for cloud computing in developing XaaS models across a private backbone vs offering Cloud-based services over the Internet.
The presenter will further discuss the potential evolution of Cloud Computing in the form of Private, Hybrid and Inter-Cloud.
Service Level Management and Security will be highlighted themes in this presentation.
The presenter will also provide an overview of the various standards organizations and forums that may be specific to cloud computing and emerging inter-cloud.
Finally, the presenter will stimulate discussion as to the value of these models to your business.
back to program ^ |
|
BGP MPLS based MAC VPN |
Rahul Aggarwal, Jim Uttaro, Juniper Networks |
|
This presentation introduces a new technology called "BGP/MPLS MAC VPN". We will describe the applicability of this technology in the data center and how it enables Service Providers to offer a new data center inter-connect service. We will also describe how this technology could be used by Service Providers to deliver Virtual Private LAN service (VPLS), and the benefits of doing so.
This presentation will describe requirements for next-generation data centers and the motivation for using BGP/MPLS MAC VPNs in the data center, and as a data center inter-connect technology. We will describe how BGP/MPLS MAC VPNs supports such functionality as active-active dual site/host homing and fast service restoration in the presence of edge failures. The benefits of control plane based MAC learning using BGP will be discussed. We will describe and evaluate various deployment options for inter-connecting data centers using BGP/MPLS MAC VPNs. The talk will also describe the IETF status of BGP/MPLS MAC VPNs.
back to program ^ |
|
Wide Area Experiment on High Performance Network Virtualization With Dynamic Configuration of MPLS/GMPLS |
Akeo Masuda, Akinori Isogai, Kohei Shiomoto, NTT
|
|
PCE and VNTM are the standard architecture that fully utilizes the MPLS and GMPLS technology.
The IP-optical TE server which we have developed based on these architectures constructs multiple
virtual networks that consist of IP links formed by optical paths connected between the pairs of IP
routers. Network resources used to setup the optical paths are separated and allocated to each virtual
network. Since the resource is isolated at the optical level, virtual networks do not affect each other
by violation such as excessive use or bursty traffic. We call this “high performance network
virtualization in IP-optical networks.”
Virtual networks can set up MPLS LSPs upon the IP links, and can optimize those routes. The
topology of the virtual network itself can also be optimized since those are composed of optical
paths that are easily set up and torn down dynamically. Topology optimization is done in response to
the change of the traffic matrix.
In order to enable these kinds of control, the network should be organized with control and data
plane at each layer, and the total management layer. IP-optical TE server should be aware of the
available bandwidth to manage the route selection and the optimization, and it also needs to
communicate with the network equipments in order to trigger the path setup signaling. For example,
OSPF-TE in the layer 3 is usually configured as an in-channel protocol. This means that the
IP-optical TE server may lose awareness of the bandwidth availability of some area in the layer 3
when it tears down a certain optical path which was that last path to ensure reachability of the layer 3
control channel.
We plan to present three topics. One is the system architecture and functionalities of the IP-optical
TE server. Another is about how we have designed and deployed the optical network including
control and management planes to enable the dynamic topology control that we aim. Finally we
introduce about the wide-area experiment of network virtualization, application triggered on-demand
path setup, and dynamic reconfiguration of the topology that we done using national testbeds and
international connections. The experiments included oversea live streaming of uncompressed HDTV
video from a broadcasting studio, and dynamic route change of a MPLS LSP which was carrying
live video stream that was being broadcasted on-air in a real television channel.
back to program ^ |
|
Large Scale Application Virtualization for Clouds |
Jerry Sobieski, NORDUnet
|
|
Large scale and globally distributed applications must address many issues beyond simply the functional objectives of the software Issues such as availability and robustness - even in a cloud environment - must be explicit in the design and actively manageable in the implementation in order for these types of services to find traction in the enterprise. Security and privacy must be not just be offered as part of an SLA, but must be quantifiable and predictable in terms of risk management and mitigation. Further, large scale applications - particularly enterprise environments - exhibit high degree of inter-dependency on similar distributed IT environments of suppliers and customers. Protecting these inter-enterprise supply chains is critical. Where as these types of IT issues have traditionally been the responsibility of software engineering and systems adminitstrators, the virtualization of applications and the floating mobility it introduces in IT services in general make these activities much more difficult. The ability to define "cloud" based applications is only just scratching the surface of virtualized cyber-resources. This talk will describe requirements for large scale distributed applications in the clouds, and work being done to formalize the design and deployment of such applications in order to address these issues.
back to program ^ |
Break & Exhibits
3:30 pm– 4:00 pm |
|
MPLS OAM architecture
|
Loa Andersson, Elisa bellagamba, IETF, Ericsson
|
|
This presentation describes the MPLS OAM architecture. It addresses issues around OAM functionality for all type of LSPs, regardless of how they have been established.
The MPLS-TP project has produced (will produce) specifications that extend the MPLS OAM capabilities and indicate how OAM messages are transported over the MPLS data plane, how nodes behave when they receive OAM messages and the structure of the OAM messages themselves.
The joint project between IETF and ITU-T has put a focus on the OAM functionality needed for the Transport Profile for MPLS. There are clearly a new set of functionality required when introducing the Transport Profile for MPLS. MPLS on the other hand has an extensive list of OAM functions that will still be in use also when the Transport Profile is completed. The MPLS OAM Framework [RFC4378] gives an overview of the MPLS OAM scenario.
Due to the number of new OAM tools provided by the MPLS-TP project it is easy to get the impression that all the MPLS OAM tools comes from the MPLS-TP project; this is not the case MPLS has a long history of OAM, e.g. LSP Ping and VCCV. This presentation describes the entire MPLS OAM Architecture regardless of where the OAM functions and tools has originated.
From the point of view of the IETF and the MPLS technology there is no real difference between an RFC developed solely by an IETF working group and an RFC developed in the MPLS-TP project.Documents from both sources contribute a single MPLS technology. Every RFC that is part of the MPLS technology needs to be compatible with the rest of the technology.
This backwards compatibility is equally relevant for the OAM functionality specified by the MPLS-TP project. Everything in the OAM specified in the MPLS-TP project is backwards compatible with the MPLS technology as it is specified by the IETF prior to the MPLS-TP project.
back to program ^ |
|
Invited Talk - OAM Analysis in MPLS-TP |
Nurit Sprecher, Nokia Siemens Networks |
|
MPLS-TP defines requirements for a comprehensive set of OAM tools for fault management and performance monitoring. These tools are intended to reduce OPEX, to enhance customer satisfaction via minimizing trouble shooting time, and to enable the delivery of high-margin premium services. The OAM tools may be used to monitor the network infrastructure, in order to enhance the general behavior and the performance level of the network. The tools may also be used to monitor the service level offered to the end customer, allowing verification of the SLA parameters, and enabling rapid response in the event of a failure or service degradation.
Existing suitable IETF and ITU-T OAM tools were evaluated against the MPLS-TP requirements in the aspects of architecture, general principles of operations, and OAM functionality. The objective of the evaluation was to identify the tools which can be extended to support the MPLS-TP OAM requirements, and to analyze the advantages of each of the candidate solutions, compared also with the option to define new tools.
The presentation introduces the required MPLS-TP OAM tools. It emphasizes the importance of having a single solution for each tool. It reviews and evaluates the different potential solutions, presenting the advantages of each. It then lays out the guidelines used for the selection of the solutions and lists the selected solutions.
back to program ^ |
|
Invited Talk - Ethernet and MPLS OAM |
Dave Allan, Ericsson |
|
Ethernet and MPLS are the dominant layer 2 and layer 2.5 technologies deployed today. Both have spent a significant amount of their deployed lifetime without comprehensive OAM capability, both depending on layer 3 tools. Over the past 5 years or so both have accreted significant OAM functionality, targeted to the modes of failure and performance monitoring characteristics associated with each.
This talk focuses on what is common and what is distinct about both MPLS and Ethernet architectures, and how this is reflected in the currently specified OAM and how it is evolving into the future. As such the talk will examine the salient features and protocol design of the 802.1ag/Y.1731 toolset, the existing MPLS OAM toolset and the emerging set of IETF tools for MPLS-TP
> Panelists from vendors and service providers will summarize highlights > and important differences and similarities between MPLS, MPLS-TP and > Ethernet OAM in terms of functions supported, operational models and > technical standards directions.
back to program ^ |
|
|
|
|
|
Panel Topic: Peaceful Co-Existence or Contiuing Competition |
Dave McDysan,
DEBORAH BRUNGARD,
Verizon, AT&T |
|
| Panelists from vendors and service providers will summarize highlights and important differences and similarities between MPLS, MPLS-TP and Ethernet OAM in terms of functions supported, operational models and technical standards directions.
back to program ^ |
|
|
|
|
Tuesday, October 27
TECHNICAL SESSIONS |
|
Backwards compatibility, options, architecture and standards - MPLS based packet transport networks |
Loa Andersson, IETF and Ericsson |
|
| Successful technologies develop over time, add new functions and capabilities. In doing so they become more capable, robust, and comprehensive. MPLS is a good example of such a successful Technology, and it is extremely well suited to stand up to new challenges and requirements. Being successful also means that when further developing MPLS, one needs to take particular care to ensure backward compatibility while not blocking further future development. This presentation will discuss backward compatibility issues in recent MPLS development.
back to program ^ |
|
Recovery Strategies in MPLS-TP |
George Swallow, Cisco |
|
Numerous recovery mechanisms have been proposed for MPLS-TP. This talk will compare and contrast Linear protection, various ring protection architectures, and shared mesh restoration. These mechanisms will be compared in terms of complexity, idle bandwidth requirements, achievable recovery times and applicability to P2P and P2MP flows.
back to program ^ |
|
LFA (Loop Free Alternates) Case Studies in Verizon's LDP Network |
Ning So, Tony Lin, Connie Chen, Verizon, WANDL |
|
The rapid growth of MPLS services (e.g. RFC 2547/4364 BGP/MPLS VPNs) and the pervasive deployment of LDP have created a need for LDP FRR (Fast Re-Route) protection. LFA (Loop Free Alternates) is an IP FRR (Fast Re-Route) mechanism that adds FRR link- and node- protection to ISIS, OSPF, and LDP. Driven by the need for rapid local repair to achieve fast recovery (tens of msec) in places where RSVP-TE is not deployed or desired (i.e. RSVP scaling problem), the major equipment vendors have recently added or are in the process of adding support for LFA according to the RFC 5286 loop-free criteria inequalities. In this talk, we look at a number of realistic LFA modelling case studies on the topology-rich Verizon network. Both flat and hierarchical topologies are examined. Crucial to the accuracy of the studies is the ability to build realistic network routing models, and to simulate failure and LFA protection in large and complex multi-protocol network topologies. We calculate the coverage that can be provided by LFA link- and node- protection, and identify places where coverage is lacking. Ways in which coverage can be extended (via both physical and virtual means) are investigated. Finally, potential drawbacks of deploying LFA (e.g., an increase in number of entries in the forwarding tabling) and situations where LFA deployment may be more appropriate than others are explored.
back to program ^ |
|
Enabling Carrier Ethernet - 50ms Pseudowire Restoration |
Kevin wang, Juniper |
|
This talk will describe a Pseudowire(PW) edge protection mechanism which can help to achieve the sub 50 millisecond end-to-end PW traffic restoration goal, irrespective of the failure location. This is a crucial building block for providing true carrier Ethernet services over MPLS.
Currently, when the links or nodes fail along the path of a PW in the provider core network, FRR protection for the transport LSP could help to fast protect the PW. However, if the failure happens in the provider edge, like the Attachment Circuit (AC) link failure or the PE node failure, existing transport LSP FRR mechanisms cannot provide protection. The proposed solution closes this gap. It is unique in the sense that it provides FRR-like local repair on the edge, thereby protecting services from both transport and edge failures.
Unlike MC-LAG which relies on control plane notifications during the failure to restore PW service, the traffic restoration in this proposal is done in the data plane, therefore faster (sub 50 ms) and more deterministic.
The scheme is built on some of the local protection concepts described in last year's Invited Talk by Yakov Rekhter (Local protection for LSP tail-end failure), on the concept of primary and protector PWs, on Upstream Label Assignment, and on Ultimate Hop Popping LSPs. The scheme will be described in detail, and actual recovery results of the implementation will be shared.
back to program ^ |
Break & Exhibits
10:30 am – 11:00 am |
|
LTE impact on the current FT-Orange design of today's 3G oriented MPLS transport infrastructure |
Frederic Jounay, Philippe Niger, Gurvan Moal, Fabien Le Clech, France Telecom-Orange Group |
|
In the context of Mobile Backhaul network evolution, FT/Orange is currently migrating legacy 2G, 3G mobile traffic (TDM, ATM)
from PDH/SDH networks to the IP/MPLS multiservice network thanks to MPLS pieces (e.g. Pseudowire).
A third traffic type (IP/Ethernet) has to be considered with 3G R5 and LTE in the mobile backhaul design.
In addition LTE introduces some new requirements on the backhaul services
(e.g. RNC removal, eNBs partial meshing, security, separate control and data plane entity, etc).
This paper aims at assessing the impact of LTE on the current design of today's 3G oriented MPLS transport infrastructure.
We will discuss the network architecture for LTE backhaul, and address the challenges and solutions in designing such a network
(topology, IP addessing, MPLS VPN, optimized auto-discovery for X2 interfaces setup, QoS, OAM in MicroWave-based backhaul,
Radio over Fiber, MPLS-TP needs ?)
back to program ^ |
|
Off loading in mobile |
Azhar Sayeed, Cisco |
|
The demand for Data on mobile devices will increase to 39x in the next 5 years. A Morgan Stanley study predicts that by 2015 mobile Internet will exceed desktop internet in terms of data volume and subscribers. As mobile and wireline provides build next generation access networks for handling large volumes of smartphone users, they just cannot do this by adding capacity to mobile networks. They are devising clever techniques to offload data from Mobile networks via the Backhaul and via Wifi and Femto to provide a quality of experience the user expects while managing the subscriber volume for voice and data. New smart devices like iPhone, iPod touch, Andriod, iPad etc have changed the landscape of content is consumed by users. This presentation looks at the data offload architecture for 3G and 4G networks with WiFi, Femto or other mechanisms. It explains the need for such architectures, and details how service providers are considering or can consider offload techniques that can help them drive better user experience and prevent a network meltdown. This presentation also details how the IP/MPLS backhaul network interconnects and transports the offload data from the packet core.
back to program ^ |
|
Meeting the Timing Requirements of Mobile Base Stations over IP/MPLS Backhaul Networks |
Peter Roberts, Alcatel-Lucent |
|
Convergence, it seems, has become the name of the game these days – having a network that can easily support today’s most in-demand applications such as concurrent video, voice and data traffic. But centralization, consolidation and virtualization are also becoming part of the networking “Holy Grail” for their equally impactful effect on network demand. MPLS has long stood out as the best single solution for WAN, with momentum that has appeared to be nearly unstoppable. However, the traditional slow-and-steady approach – using legacy technologies and suppliers along with long-term static bandwidth contracts – is no longer a viable option for enterprises that need to communicate across multiple (and sometimes remote) geographies.
Today, a high level of agility and interoperability isn’t just nice to have, but a must have – requiring organizations to identify the best suppliers and technology options in order to effectively meet and adapt to ever-changing business needs. But how does one determine the right mix of networking technologies to address these requirements in a cost effective, yet scalable manner? In this presentation, Reliance Globalcom CTO Dr. Kamran Sistanizadeh will address:
- The geographic reach, performance and cost factors driving the adoption of MPLS and its alternatives
- The ideal environment and requirements for the adoption of a hybrid solution, or the coexistence of MPLS, Ethernet and Internet VPN, a mix of Layer 2 & Layer 3 – previously disparate technologies, now able to co-exist as a single and highly effective network design
- How enterprises should evaluate all technologies when facing a broad choice of options for network management: MPLS, Ethernet-based alternatives, VPLS, 3G mobile broadband, and in many markets, WiMax and high-speed Fiber to the Building
When to employ an MPLS backbone to operate a global Ethernet network for a secure and scalable networking solution, and when to employ a global VPLS core.
back to program ^ |
|
Towards efficient “homeless” MPLS mobility with identifier/locator seperation |
Wassim Haddad, Joel Halpern,
Ericsson |
|
In the current Internet architecture, enabling ongoing sessions to survive an IP address change has been perceived to a large extent, as an IP-layer problem. IP mobility solutions are designed around two main concepts: a static “home agent” and IP-in-IP tunneling. Multiple IP-based mobility solutions have been standardized but only few are already deployed.
With the ongoing efforts to re-architect the Internet around the identifier/locator split concept, we take a fresh look at network-based micro-mobility by focusing on the impact of implementing such concept at the end-hosts side while moving within the same or different MPLS-enabled domains. Our interest in micro-mobility stems from analytical results showing that mobility has a local scope in most of the cases.
With this picture in mind, we investigate how to dynamically establish and configure necessary MPLS tunnels between a mobility anchor node located in the same domain as the mobile endpoint, without involving the latter in any mobility-related signaling exchange.
In addition, communication between the two mobile endpoints, i.e., inter-domains, is achieved by leveraging the identifier/location split concept at the network infrastructure side. The overall architecture provides a clean(er) separation between nodes functionalities and allows greater flexibility in terms of providing additional features, e.g., traffic engineering, virtual private network, privacy, etc, while minimizing the amount of signaling messages.
In this talk, we present a new network-based micro-mobility design, which is centered around implementing an id/loc split at the mobile end-host side and deploying MPLS technology within the domain. While such design does not require a static home agent as it allows the mobile endpoint to keep the same identity virtually everywhere, it allows dynamic assignment of temporary one(s) depending on the mobile node’s topological location. Then, we discuss the design impact on the communication between the mobile endpoint and the associated mobility anchor node as well as between the two mobile endpoints via their corresponding mobility anchors. Compared to previous IP-based mobility protocols, our new protocol enables a simpler yet more efficient, scalable and secure handoff design which is better suited for next generation wireless networks.
back to program ^ |
Lunch & Exhibits
12:30 – 2:00 pm |
|
Flexible and Scalable Wholesale Services on an End-to-End MPLS based Network |
Nicolai Leymann,
Deutsche Telekom |
|
During the last years MPLS extended from the core towards aggregation and access networks in order to provide an end-to-end platform for a variety of different services. DT is currently migrating it’s network towards “Seamless MPLS” for residential and business services. Seamless MPLS also provides an ideal platform for wholesale services for single, double and triple play customers. This presentation explains wholesale models on top of MPLS and will cover the following topics in detail:
• Requirements for single, double and triple play wholesale services: Detailed view on service requirements of wholesale customers; explains the impact on network design and the Seamless MPLS architecture.
• Wholesale Models: Explains how wholesale services can be supported with Seamless MPLS (including the support of wholesale models for Multicast traffic). Compares different options and addresses requirements like scalability, the need for flexible service creation points (centralized vs. decentralized) and redundancy for wholesale traffic.
• Virtualization of Multicast Traffic: The support of end to end Multicast traffic carried over MPLS to 10.000th of nodes is still a challenge. The proposed solution supports the transparent use of Multicast addresses, supports wholesale services and controls the use of resources within access and aggregation nodes.
back to program ^ |
|
Multicast deployment in Telus |
Boris Zhang, Telus |
|
More and more customers are asking for native multicast support from their service providers. Service providers need to choose from various available multicast standards and technologies based on their infrastructure and applications which have significant impact in the choice of different control plane and forwarding layer technologies. In designing their core networks to support native multicast, service providers have to address design challenges such as multicast traffic replication within their networks, multicast to tunnel mapping , multicast multi-topology , multicast access network, multicast RP placement , inter-AS multicast etc. In most of the scenarios, all these issues need to be addressed within the confines of existing MPLS backbones and Metros while not losing sight of traffic engineering, QoS, service performance, resiliency and availability.
This paper explores above mentioned design challenges based on TELUS MVPN service development experiences and proposes enhancement to address design challenges in area of QoS, sampling & analysis, redundancy, timer optimization, Extranet, site restriction, IPv6 multicast, migration plan and expansion. Multicast security design at protocol level such as IGMP, PIM and BGP and forwarding cache level are also discussed.
Based on our experiences obtained from implementation, the follow topics are highlighted.
Optimize multicast route and forwarding in the core
- BGP based auto discovery and c-multicast route exchange help to leverage knowledge and investment on L3VPN services
- MPLS based I-PMSI/S-PMSI helps to integrate TE enabled backbone and mitigate flooding by creating/pruning LSP branches dynamically
Optimize multicast access in the metro
- Use incongruent access by separating unicast and multicast service topology to contain multicast traffic local within the region without congestion metro’s connection back to PE
- Overcome multicast flooding in Metro network by ensuring that metro devices support PIM Snooping
Redundancy
- Provide sender and receiver PE gateway redundancy via a pair of devices in each site
- Explore possible link and protocol failure to evaluate the resiliency with taking protocol timer into account;
Migration
- Seamless migration of customer multicast application spanning provider networks via flexible RP placement by offering any cast RPs in PEs while not limiting customers from using their own RPs
- Seamless migration of provider network spanning evolving P-tunnel technologies.
As a comprehensive MVPN service implementation case study, this work elaborates key aspects of design by covering architecture, detail design, design optimization, scalability and security which make it a valuable reference for any analogous application.
back to program ^ |
|
BGP MVPN Deployment - Case Study |
Mazen Khaddam,
Cox Communications |
|
This talk describes Cox’s deployment of BGP MVPN for hierarchical VoD library distribution from national video head-end to regional video head-ends. The talk will describe the reasons for choosing BGP MVPN technology for this application. It will describe the convergence characteristics that are required by the application and how they are met by the BGP MVPN control plane and the P2MP MPLS TE data plane. The deployment design of the BGP MVPN control plane and the P2MP MPLS TE data plane will also be described. This will include how I-PMSIs and S-PMSIs are used.
back to program ^ |
|
Ethernet Broadcast & Multicast on VPLS - Can carriers propose a simple approach? |
simon Delord,
Telstra |
|
VPLS existing standards have well known limitations in terms of traffic replication when it comes to Ethernet multicast and broadcast frames.
While these limitations may not be a deterrent when Ethernet broadcast/multicast traffic volume is low or the number of PEs in a given VPLS is small, they may quickly become a lot more difficult to accept for carriers introducing applications with substantial Ethernet broadcast/multicast traffic (such as HD TV) .
This problem may even get worse as MPLS networks expand from the core towards
aggregation/access with potentially more PEs participating in a single VPLS.
The BGP-VPLS-Multicast [1] solution addresses the challenges of IP Multicast over VPLS (including Ethernet multicast/broadcast), however this solution requires the carriers running LDP-VPLS [2] to add BGP.
In a world where time to market as well as OPEX and CAPEX constraints are critical to survival, some carriers are collaborating to see if some simple, non fully-dynamic optimisation mechanisms can be used to achieve some quick wins. Is there an intermediate alternative for such carriers that can still meet their key requirements?
This presentation will look at the following specifically for those carriers in the particular context of existing LDP-VPLS implementations:
- What are the key requirements that need to be addressed for Ethernet broadcast/multicast on VPLS
- Why a non fully-dynamic approach to optimise Ethernet broadcast/multicast may be acceptable and sufficient
- How to use P2MP PWs incrementally to the existing full mesh of P2P PWs and the associated modifications to VPLS
- Some use cases: Video distribution, clock synchronisation.
[1] draft-ietf-l2vpn-vpls-mcast
[2] RFC 4762
back to program ^ |
Break & Exhibits
3:30 pm – 4:00 pm |
|
Considerations for service providers to deploy P2MP RSVP-TE and MLDP for multicast applications |
Pradeep Jain, Pranjal Dutta, Sandeep Bishnoi, Alcatel-Lucent |
|
P2MP RSVP-TE
RSVP-TE is the preferred transport method in deployments that require strict SLAs. Major benefits of RSVP-TE are traffic engineering, resource reservation and fast failover.
There are some major disadvantages too like per LSP explicit configuration, periodic refreshes, higher number of control plane states which affects scalability etc.
Explicit configuration problem becomes severe in case of point-to-multipoint LSPs for applications that use manually provisioned P2MP LSP. Each leaf node requires explicit configuration for applications that do not have a way to discover leaf nodes dynamically. Configuration overhead for applications that have auto-discovery method built-in can be reduced by using template based LSP creation.
There are other disadvantages like setup of parallel streams within a single multicast tree, which eventually gets blocked when the parallel streams remerge along the traffic path. Extra replication of traffic in network from branch point to a remerge node eventually goes wasted is major disadvantage of P2MP RSVP-TE. Creation of parallel streams over a single tree and remerging can be eliminated by using tree based CSPF computation algorithm.
MLDP
LDP is the preferred transport method in deployments that require best effort label switched forwarding of traffic. Benefits of LDP include less control plane state, no periodic refreshes, no per LSP configuration etc. Other features that were available only with RSVP-TE are now being proposed for LDP. Fast-upstream reroute with sub-50ms failover time is now available with LDP by leveraging existing methodologies like look-free-alternative, ECMP, load balancing etc. Such mechanisms also provide upstream node protection to avoid single point of failure.
Major benefit with P2MP LDP is advantage of control plane merging. The nodes that are closer to the source have lesser state to maintain so are able to scale much higher. Data plane and control plane state for P2MP LSP is one-to-one so they can potentially scale up to the level of P2P LSP.
MLDP also has a provision to setup multipoint-to-multipoint LSPs. For multiple site applications like MVPN, a single multipoint-to-multipoint LSP can suffice instead of creating a mesh P2MP LSP from all nodes.
Analysis of Multicast Applications
Various multicast applications that providers currently offer -
- Managed enterprise MVPN services
- Video distribution by content provider
- Service provider managed digital signage service
We would discuss specific application requirements like bandwidth, application provision flexibility, resilience etc.
Analysis of P2MP LSPs based on application requirements
Though P2MP RSVP-TE and LDP have their own advantages, there is no clear winner. It is dependent on type of application that would dictate preference of one over the other. In this section we would discuss applications like MVPN, VPLS, Multicast in base instance and their specific requirement from transport LSP.
We would do analysis of each based on parameters like – LSP provisioning, control plane and data plane scaling, resilience etc.
back to program ^ |
|
Leveraging BGP for multicast VPN monitoring and trouble-shooting |
Thomas Morin, Cengiz Aleattinoglu,Packet Design, France Telecom-Orange Group |
|
Deploying IP multicast VPNs remains challenging as there is a lack of good set of monitoring and diagnosis tools. Traditional SNMP-based monitoring tools do not handle the high dynamics in IP multicast VPNs, and have scaling issues. In this presentation we focus on building monitoring and diagnostics tools that leverage the MP-BGP multicast VPN route announcements and withdrawals in the service provider network. We present how these tools can assist the operator in successfully deploying IP multicast VPNs.
This is a natural extension of approaches already used for unicast VPN monitoring. However, because the nature of the auto-discovery and routing information being carried by multicast VPN routes is different, the use cases of this information, the challenges for exploiting it, and the end benefits of the approach are interesting to study.
We will illustrate the benefits of such an approach for statistics and reporting, such as number of multicast enabled VPNs and VRFs, number and nature of P-tunnels, dynamics of customer multicast routing state changes, as well as the benefits for anomaly detection through consistency checks, and for diagnosis purpose.
The challenges essentially relate to how the information is exploited and interpreted in conjunction with information on unicast VPN routing, and how the multicast VPN routing information hidden by BGP route reflector processing can be retrieved for finer grained monitoring.
Beyond purely BGP-based monitoring we'll explore how this information can be coupled to monitoring information related to other protocols, such as the protocols used for provider tunnel signaling, the IGP and OAM protocols.
back to program ^ |
|
Point-to-Multipoint Layer-2 video transport over MPLS |
Santiago Alvarez, Cisco |
|
This session describes a layer-2 video solution using MPLS. Recent developments in Pseudowire technology enable a new type of layer-2 multicast service. This presentation will discuss the details of traffic forwarding in the MPLS network and how the solution integrates with layer-2 and layer-3 protocols. Lastly, the mechanisms available for service resiliency will be discussed within the context of different failure scenarios.
back to program ^ |
|
|
|
|
Wednesday, October 28
TECHNICAL SESSIONS |
|
Proposal of the MiDORi GMPLS Traffic Engineering for Energy Optimal Traffic Controlled Networks |
S. Okamoto, KoU Kikuta, D. Ishii, E. Oki, N. Yamanaka,
Keio University |
|
This presentation describes newly developed GMPLS extensions for realizing energy optimal traffic engineering technologies. We are developing “MiDORi (Multi- (layer, path, and resources) Dynamically Optimized Routing) Network Technologies” that is composed of a low energy consumption network design tool (MiDORi PCE), GMPLS extensions (MiDORi GMPLS) for controlling network equipment and a MiDORi router/switch controlled by MiDORi GMPLS. “midori” is a Japanese word which means “green” in English. In the presentation, the detail GMPLS extensions (OSPF extension, RSVP extension, and LMP extension) and experimental results of MiDORi Network Technologies will be presented.
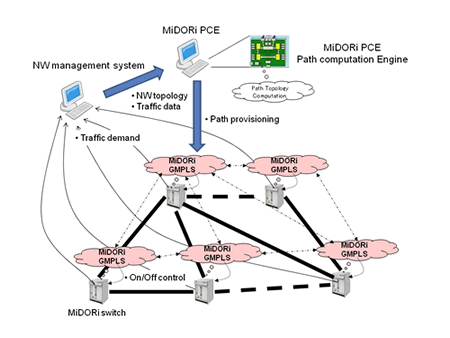
Fig 1: MiDORi network system concept.
back to program ^ |
|
Analyses and Further Development of MPLS-TP OAM Tools for Carrier Grade Operation |
Yoshinori Koike, Makoto Murakami, NTT |
|
MPLS-TP is one of the most promising technologies for next generation packet transport network. MPLS-TP has been positively discussed and developed between IETF and ITU-T. Among MPLS-TP functions, OAM(Operation, Administration and Maintenance) is the most essential feature, therefore in this presentation we analyze some OAM functions and promote technical discussion for further development.
First, MPLS-TP OAM functional requirements are specified in the MPLS-TP OAM requirement I-D and MPLS-TP OAM framework I-D in IETF. Most of the measurement functions are already covered by OAM frame-based functions. However, there are two similar OAM functions which are an on-demand OAM message loopback and a data-plane loopback. It is not always the best choice to implement all the OAM toolsets in terms of cost effectiveness and test conditions. In that case, the data-plan loopback function can be an effective and necessary function. As we can see in the above, we compare the characteristics between data-plane loopbacks and OAM message loopback and elaborate on the differences by particularly focusing on operational benefits.
Second, to verify and maintain performance and quality guarantees on arbitrary parts of transport paths (e.g. label switched path (LSP) or mult-segment pseudowire (MS-PW)), path segment tunnels (PSTs) are supported in multiprotocol label switching transport profile (MPLS-TP) networks, which can also be used to meet the requirement to provide tandem connection monitoring (TCM). When operators would like to monitor the arbitrary parts of transport paths between any two arbitrary points along a transport path, the in-service creation of a PST or TCM on existing LSPs without traffic disruption is required as an effective maintenance tool, and this is achieved using make-before-break procedures. However, there are some concerns from the perspective of intrinsic monitoring features. We clarify the requirement for in-service configuration for monitoring and suggest a possible solution to solve a problem.
Finally, NTT proposed a per-interface model and the model was newly introduced for enhanced maintenance abilities in MPLS-TP OAM framework. However, most of the current specifications in MPLS-TP are described on the basis of per-node model. Therefore, this presentation also elaborates on the features of per-node model, focusing on distinctive characteristics in the model.
back to program ^ |
|
Does OTN really make sense for Router Bypass?
|
Ori Gerstel, Rob Batchellor, Clarence Filsfils, Cisco |
|
Optical Transport Networking (OTN) is a circuit switching technology that replaces SONET/SDH for higher bit rates. Until recently OTN was used for point to point transmission of client signals over optical networks, but now the industry is moving toward using OTN to provide a full networking infrastructure for high speed connections. The most prominent use case for OTN is to deliver Layer 1 high speed private line SONET or Ethernet services. A lot of the research has been focused on whether OTN can reduce the cost of the IP layer by bypassing core routers for traffic that just goes through the site (hollow core). In this presentation we outline the main considerations that must be taken into account to accurately assess the value of OTN for the IP layer and show their impact on a real-world large Service Provider network.
back to program ^ |
|
MPLS Openflow and the Split Router Architecture: A Research Approach |
Howard Green, James Kempf, Sonny Thorelli,
Attila Takacs, Ericsson Research |
|
Merchant silicon switch chips are becoming increasingly capable, gaining the ability to handle MPLS and basic IP as well as Ethernet, and providing very high bandwidth (e.g 64x10Gb/s) at moderate cost. At the same time, the demands on the routing and switching control plane are becoming more complex. Operators want the ability to customize routing to handle specific kinds of traffic flows near the edge, configure customized services that span aggregation networks, and achieve packet/opto integration, without the detailed low-level configuration typical of today’s networks. These trends suggest a different approach to routing architecture, in which the control plane is handled by a centralized server and the data plane consists of simplified switch/ router elements “programmed” by the centralized controller. The centralized control approach also may solve issues involving long convergence times, unnecessary interactions between the different control mechanisms, and sub-optimal recovery and OAM at each layer that occur with the interaction between distributed control plane mechanisms such as BGP, IGPs, LDP, and STP/MAC learning. We call this the split router architecture.
This approach to splitting the control and data plane is somewhat different from (but complementary to) GMPLS, in that a “vertical” switch control protocol connects the switching elements to the controller, (as in some optical network GMPLS configurations) while a “horizontal” control plane protocol, which may in fact be GMPLS, federates networks under the command of a controller and standard routers where necessary. The advantage of this architecture is that customized control plane applications can be more easily and cheaply implemented on a server than on multiple monolithic router control software platforms, and that high level policies may be consistently expressed and implemented.
In this talk, we discuss some experiments designed to explore technical issues with the split router architecture and, in particular, the role played by MPLS. We highlight OpenFlow, a current research initiative toward a vertical control protocol, and NOX, an open source network controller. We present an experimental MPLS extension to OpenFlow implemented at Ericsson Research. We describe a low-cost MPLS label switched router (LSR) implemented with MPLS Openflow, and present an MPLS OpenFlow network controller that can be used to control a collection of LSRs, and a design and implementation of BFD protection on an MPLS OpenFlow LSR. We illustrate how MPLS Openflow and the split router architecture could be used to solve some problems in deploying MPLS-TP in operator networks.
back to program ^ |
Break & Exhibits
10:30 am – 11:00 am |
|
Some Controversial Issues about MEF E-Tree Over MPLS – From the Perspective of Service Providers |
Raymond Key, Frederic Jounay,
Telstra, France Telecom |
|
In 2004 MEF published the Ethernet Services Definitions Phase I (MEF6) and defined the service type E-LAN. Considerable number of service providers have adopted VPLS (IETF standards RFC4761 or RFC4762) to provide E-LAN services to customers over their MPLS network. In 2008 MEF published the Ethernet Services Definitions Phase 2 (MEF6.1) and defined a new service type E-Tree. The only difference between E-Tree and E-LAN is that E-Tree prohibits Leaf-to-Leaf communication. Some major E-Tree use cases are content delivery, Internet access, IEEE 1588 clock synchronisation, hub & spoke VPN and wholesale access.
At first glance, the difference between E-Tree and E-LAN is minimal therefore it should be easy to provide both types of services on an existing VPLS/MPLS infrastructure. The reality is, two years after MEF defined E-Tree, service providers are yet to find a satisfactory solution.
There are five individual drafts on this topic submitted to IETF. In the IETF77 conference, two proposed solutions were presented in the L2VPN working group. More service providers have expressed their desire for a simple solution that can be easily integrated into their existing VPLS/MPLS infrastructure. Collaborations are happening publicly in standards organisations and also privately among service providers and vendors.
This presentation will discuss some controversial issues from the perspective of service providers, in particular the vast majority of small and medium size ones.
The Problem “Corner Case” - Two or more PEs with both Root and Leaf
- Is the current standard VPLS really insufficient?
- Is this an incredibly rare case that we can manage to avoid?
- Should we modify the service definition to “single Root only” in order to eliminate the problem?
E-Tree Service Definition
- Should we adopt the MEF service definition?
- Should we consider “extended” service definition beyond MEF’s? Example: Leaf Group extension - allow communication within Leaf Group; prohibit communication across Leaf Groups
IETF or IEEE
- Is this a problem for Ethernet or VPLS, or both?
- Should the problem be solved in IEEE or IETF, or both? Which one first?
Different Solution Approaches
- Ingress Tag, Egress Filter
- Asymmetric VLAN, Shared Learning
- Separate Root VSI and Leaf VSI, no PW between Leaf VSIs, PE local split horizon rule
Virtual Private Multicast Service (VPMS)
- Will the E-Tree requirement be fulfilled by the work-in-progress VPMS?
One Requirement Model Only
- Different deployment scenarios, single or multiple technologies involved
- Should we avoid duplication and multiple solutions where possible?
- Should we have one agreed requirement model in order to ensure one best solution only?
The presentation will conclude with a case study on a service provider in Asia Pacific.
back to program ^ |
|
Using a Policy driven ‘Selective Offload’ paradigm to address Mobile traffic explosion |
Pasula Reddy, Fujitsu |
|
As mobile data traffic increases exponentially, carriers are looking at new ways to keep up with the ever growing bandwidth requirements – both in their backhaul networks and also in their mobile packet core networks.
One approach to keeping the problem in check is to be able to distinguish revenue generating vs. non revenue generating traffic - as early as possible and as close to the mobile device as possible. This allows carriers to utilize their transport networks more efficiently by selectively offloading (based on a set of policies) certain types of (non revenue generating) traffic from their choke points, which in turn allows them to reduce overall traffic load in their backhaul and mobile core networks.
This same concept can also be extended to wireline (non mobile) traffic, thereby allowing carriers to build next generation networks that can address the needs of both wireline and wireline traffic.
It is unlikely that every carrier will follow the same architecture, but this presentation will describe several options – based on a variety of factors such as --
- End user SLAs and how they relate to a policy driven offload architecture
- In-franchise vs. out of franchise networks
- Access, Aggregation, Metro Core, Regional and National networks – when and where does it make sense to offload traffic from each of these networks, depending on where the potential choke points are
- Centralized vs. Distributed ‘intelligence’ layer and cost-implications
- Applicability to 3G and 4G networks
- Identification of traffic type (revenue generating vs. non revenue generating)
- QoS implications
- Wholesale vs. Retail services
- Inter-carrier agreements
- Transport cost/bit in different parts of the network
- End user SLAs and how they relate to network policies
- Wall gardened services and security implications
This presentation will describe how Layer-0/1, Layer-2, Layer-2.5, Layer-3 and Layers 4-7, each play an important role (and provide toolkits) in enabling such architectures. It explains how a Policy driven forwarding paradigm combined with the traditional L0/L1/L2/L2.5/L3 forwarding paradigm can lead to very efficient network architectures, that can address both current needs and (more importantly ) the needs of the future.
back to program ^ |
|
The Role of MPLS-TP in Mobile Backhaul
|
Lubo Trancevski, Alcatel-Lucent |
|
The explosion of mobile networks usage and proliferation of bandwidth-hungry data services is driving the evolution towards LTE. LTE will bring several radical changes to the mobile network infrastructure: much increased bandwidth; pure packet operation, including VoIP; flattened architecture and all IP RAN. These changes in turn introduce new radical requirements on the network infrastructure both in the backhaul and the in the packet core. First introduction of LTE will likely happen in the form of hot-spots within existing 2G/3G network, thus further increasing the strain on the microwave and cable/fiber backhaul infrastructure that is currently in place.
MPLS-TP is currently being standardized to offer connection-oriented, carrier-grade transport for packet services. It is based on transport profiling of the widely deployed IP/MPLS protocols, resulting in a set of protocols meeting the requirements of transport networks. MPLS-TP exhibits comprehensive OAM with support for performance monitoring; fast protection switching in the data plane; separation of the control and data plane; IP-less and IP-based mode of operation; and operation through the control plane and through a centralized NMS. This, MPLS-TP is ideally positioned to help with the transition of transport networks to packet transport, as well as provide interconnection with the IP/MPLS aggregation and core regions.
This paper will examine the impact of LTE on the backhaul networks. Several aspects will be investigated, specifically, support for services and L2VPNs, QoS, protection, security, synchronization and interworking with the ePC. For each of the above, it will be shown how MPLS-TP provides excellent support. Special emphasis will be placed on showing the interoperability between both wireless and wireline part of the backhaul and aggregation networks using functions from MPLS-TP.
back to program ^ |
|
TDM Migration and the Path Towards Unified Networking |
Eylon Sorek, Orckit |
|
It is common knowledge that telecommunication service providers worldwide have transport networks that were originally designed to deliver TDM services. Yet due to the exponential growth in data services we have experienced over the past few years, next-generation transport is facing scalability and cost challenges and therefore embedding packet capabilities.
In order for telecom service providers to preserve their TDM services, know-how and investment, it has become increasingly obvious that some kind of a migration plan is needed. One such approach would be to emulate TDM in packet-based switches and routers. In line, another option would be to embed packet technologies such as Ethernet and MPLS into the traditional transport systems.
This presentation will provide analysis on the current and future TDM plus packet services delivery over networking infrastructure, comparing several alternatives and describing how phased migration can be done with circuit emulation technologies in order to achieve the most scalable and affordable MPLS networking environment.
back to program ^ |
Lunch & Exhibits
12:30 – 1:30 pm |
|
Ten+ Years of MPLS: A Retrospective Deployment Survey |
Arman Maghbouleh, Cariden |
|
A wealth of information is available about MPLS standards, but little information is available about what is actually deployed and why. This study presents the results of a survey of 59 telecommunication service provider networks worldwide. The survey results confirm the success of MPLS as a basis for service delivery and traffic engineering. The results also point to interesting findings such as vendor preferences in MPLS protocol choice, more variation in protocol choice for Layer 2 services than Layer 3 services, perseverance of single-service networks alongside multiservice networks, a tendency for keeping to the basics as much as possible, and extremely long adoption cycles.
back to program ^ |
|
Sub-50 msec Fast-reroute (FRR) of mLDP and Multicast Traffic |
Zafar Ali, IJsbrand Wijnands, Cisco |
|
As multicast service deployments grow in number and size, service providers are looking for solutions that minimize the service disruption due to network faults. This presentation outlines a framework for fast-reroute (FRR) mechanisms for multicast traffic to protect against link or router failure by invoking locally determined repair paths or predetermined redundant paths in the network. This is to allow the failure to be repaired locally by the router(s) detecting the failure without the immediate need to inform other routers of the failure. In this case, the disruption time can be limited to the sub-50 msec taken to detect the adjacent failure and invoke the backup routes. This is analogous to the FRR technique employed to protect MPLS LSPs signaled by RSVP-TE protocol [RFC4090], [RFC4875]. However, unlike RSVP-TE FRR, the proposed mechanisms are applicable to a network deploying mLDP and native multicast services.
mLDP FRR is a mechanism that enables a router to rapidly switch mLDP traffic following an adjacent link and/or node failure, towards a pre-computed backup. The backup can be an RSVP-TE signaled LSP or can be a loop-free alternative (LFA) path. This allows the backup path to be also SRLG diversed. When a local failure is detected by the upstream router, it starts to send the traffic over the pre-computed/ pre-programmed backup. While FRR is active and traffic is flowing through the backup path, the downstream router tries to find an alternate path towards the root of the tree. Once an alternate path towards the root of the tree is found, traffic is moved from the FRR backup path to the new converged path in a make-before-break fashion. This allows mLDP to achieve fast reroute with only sub50 msec traffic loss.The presentation describes mLDP FRR technique in detail. The presentation also outlines mLDP make-before-break capability and describes how it can be use minimize traffic loss in failure scenarios.
The presentation also describes how sub-50 msec of fast routing can be achieved for native multicast traffic using MoFRR technique. The basic idea of MoFRR is to send a secondary join to a different upstream interface. The network then receives two copies of the multicast stream over two separate and redundant paths through the network. When a primary path fails, downstream node can switch over to the backup path based on the local interface failure notification, instantaneously. As the switchover decision does not require sending a new PIM join, sub-50 msec of switching performance is achieved. The presentation outlines the MoFRR technique in detail. IGP-based MoFRR that does not require transmission of redundant stream is also discussed in this presentation.
back to program ^ |
|
MPLS-TP: Will it make or break your network |
Joe Zeto, Ixia |
|
MPLS-TP adds transport-like operation, OAM, and resilience to carrier-class MPLS technology making it an attractive option for access, aggregation and backhaul networks supporting broadband, business and mobility services. But before service providers replace or upgrade their existing SONET/SDH/DWDM transport network with MPLS-TP there are many critical questions surrounding implementation that must be satisfied. Service providers need assurance that the new packetized network will meet requirements in terms of reliability, operational simplicity, quick service provisioning, and end-user QoE. This presentation reviews how network equipment vendors and service providers alike can assess the viability of MPLS-TP on their device or network. We will review the issues and test plans surrounding MPLS-TP deployment, including interoperability, OAM, APS, MS-PW, MPLS and MPLS-TP internetworking.
back to program ^ |
|
|
|
|
|
|
|
|
