Thursday, November 1
TECHNICAL SESSIONS |
|
SDN Architectural Overview |
Christopher Liljenstolpe, Big Switch Networks |
|
back to program ^ |
|
Where The Network Operational Rubber Meets the Road: IRS, OpenFlow, and Network Programmability |
Tom Nadeau, Juniper Networks |
|
The IRS protocol and related components are being created at the IETF to act as a means of programming a network device's Routing Information Base (RIB) using a "fast path" protocol that allows for a quick cut-through of state manipulation operations in order to allow for "real-time" interaction with the RIB and the RIB manager who controls it. Previously, the only access one had to the RIB was via the device's configuration system (i.e.: Netconf, CLI or SNMP). Another key sub-component of IRS is normalized and abstracted topology. The goal here is to represent topology by defining a common and extensible object model. The service also allows for multiple abstractions of topological representation to be exposed. Another key aspect of this is that non-routers (or routing protocol speakers) can more easily manipulate and change the RIB state going forward. Today non-routers have a major difficulty getting at this information at best. Going forward, applications such as components of a network management/OSS, analytics, or other applications we can't yet envision will be able to interact quickly and efficiently with routing state and network topology.
This presentation compares and contrasts these new functions and features with those available in OpenFlow, and other SDN solutions within the context of network operations. Given that one of the key goals around SDN (driven and defined) is operational optimization and efficiency, the key to the success of any SDN solution is successful deployment. This presentation will discuss some examples of how this might be achieved.
back to program ^ |
|
The Virtual Network, A Pragmatic Look at SDN |
Mark berly, Arista Networks |
|
Software Defined Networking (SDN) is still in its formative years with a multitude ideas on how to implement it and the problems it solves. In this session we will take a pragmatic look different methods of achieving SDN and the interaction with the physical network; while not ignoring the criticality for a stable control and data plane and tools to take SDN architectural ideas into production and solve the associated operational challenges.
back to program ^ |
|
EVPN Support for Cloud |
David Allan, Ericsson |
|
The addition for support for 802.1aq to EVPN is now being specified in the IETF L2VPN WG. The manner in which it enables interworking between 802.1aq, 802.1ah, PBB-MES and the future 802.1Qbp standard means that massively scalable L2 networks supporting cloud, MEF services and L2VPNs can now be seamlessly constructed through a combination of Ethernet and MPLS. The combination of MACinMAC, and EVPN effectively provides a multi-area solution with summarization of multicast state, dramatically increasing the scaling achievable with Ethernet by literally multiple orders of magnitude The presentation focuses on the fundamentals of 802.1aq SPBM support over EVPN. There is a particular focus on the mechanics, how operational decoupling of the Ethernet networks is achieved and how this permits the integration of Ethernet SPBM, PBB and PB networks.
back to program ^ |
|
Multi-Layer Integration Using SDN |
Ping Pan, Infenera |
|
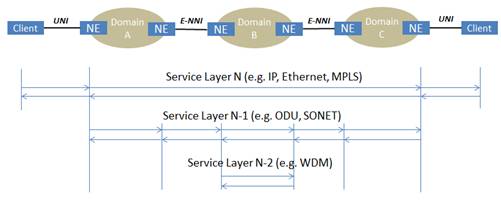
Multi-layer integration has always been a challenging issue for service providers. Many standards bodies and vendors have proposed of deploying GMPLS-UNI and E-NNI to inter-connect IP/MPLS/GMPLS domains in an integrated and coherent fashion, as illustrated above. Unfortunately, they rarely get deployed for a number of reasons. One key challenge is due to the fact that the network devices need to support and inter-operate multiple types of technologies that operate at different service layers, in order to support the “peering” UNI/NNI models.
With the emerging of SDN, we envision that the multi-layer integration can be resolved in a “hybrid” model, as illustrated below:
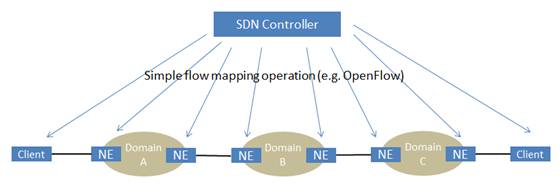
- IP/MPLS/GMPLS will continue to operate within each domain
- The interface between clients and domains is now driven by the SDN Controller, and thereby becomes a simple over-lay model:
- At data-plane, traffic is mapped from one domain into a set of “virtual” interfaces at the edge of the adjacent domains
- The control-plane is responsible for gathering network topology data and deciding the optimal traffic mapping from one domain into the “virtual” interfaces
- Further, the control-plane is responsible for interfacing with the network edge nodes to provision the appropriated connections.
The new approach introduces operational simplicity, as each domain simply presents simple “virtual” interface information to the centralized SDN controller, which is owned with the service providers.
We are currently working with a number of service providers on the details of this SDN WAN solution.
back to program ^ |
Break
10:30 am – 10:45 am |
|
Cloud and SDN |
Peter Krey, Fidelity Investment |
|
back to program ^ |
|
Network Analysis with SDN Tools |
Truman Boyes, Bloomberg |
|
This talk discusses considerations in building a flexible packet capture network using OpenFlow and SDN-related technologies. This talk is geared for consumers of SDN technologies and presents some readily available methodologies for quick time-to-market implementation.
back to program ^ |
|
TE in an SDN Context |
Mohan Nanduri, Microsoft |
|
back to program ^ |
|
Network Control Using SDN |
Afrakhteh Arash, Cariden Technologies
|
|
back to program ^ |
|
OpenFlow/SDN technologies for Flexible and Cost-effective Transport |
Atsushi Iwata , NEC Corporation |
|
The author presents OpenFlow/SDN technologies for transport network. Existing OpenFlow/SDN products have been applying to cloud/datacenter markets, or closed domain network, at the first commercial deployments. Due to large demands of its application to wide area network by telecom operators, there have been several activites for those areas. In this presentation, the author introduces NEC's current cloud/datacenter products (ProgrammableFlow) overview, and then presents several NEC's OpenFlow/SDN carrier's use cases and those prototype systems: (1) OpenFlow/SDN-based MPLS-TP network control for transport network and (2) OpenFlow/SDN-based network control for mobile core network as a virtualized mobile core.
back to program ^ |
Break
12:15 – 1:30 pm |
|
GICTF Activity to Promote Inter-Cloud Technologies and Standards |
Tomonori Aoyama, Keio University
|
|
Global Inter-Cloud Technology Forum (GICTF) was established in Japan, July 2009 to promote R&D on inter-cloud technologies and standardization. GICTF is publishing white papers to describe use cases of inter-cloud frameworks, clarify required technologies for federating different clouds, and propose standards of specifications for interfaces among clouds. GICTF is actively proceeding with collaborations among other SDOs for cloud standards in the world. This talk presents the need for inter-cloud to handle big data, and introduces the outcome of the GICTF activities.
back to program ^ |
|
DMTF Activities and DMTF/GICFT Collaboration in Inter-Cloud |
Jeff Hilland, DMTF President |
|
This presentation will cover interoperable cloud standards being developed by the DMTF, ongoing work with DMTF alliance partner GICTF and the opportunities that present themselves around cloud standardization.
back to program ^ |
|
SDN based Cloud Service by Carrier/Service Provider
|
Yoichi Sato, Ichiro Fukuda, NTT Communication |
|
NTT Communications deployed SDN based Cloud Service to its data centers as part of OpenFlow/SDN initiative. We allow self provisioning by our customers via web portal which provides the benefit of work flow improvement such as shortening service delivery and reducing provisioning time. We also apply OpenFlow to inter data center networks in order to provide data backup, migration services, and flexible bandwidth control between data centers.
This presentation also discusses OpenFlow/SDN based technology named "BGP Free Edge". BGP Free edge was architected and developed by NTT Multimedia Communications Laboratories, Inc. Silicon Valley (a NTT Communications' R&D subsidiary). Using this technology, we are planning to expand networks in the data center, as well as deliver low cost service point of presence locations in the WAN.
back to program ^ |
Break
2:45 pm
– 3:00 pm |
|
Inter-Cloud and Architectural View from the ITU-T |
Monique Morrow, Cisco Systems
|
|
|
The speaker will provide an overview of the inter-cloud ecosystem and the emerging architecture as currently being discussed within the ITU-T. The more pivotal questions that should be posed are around implications to interoperability; security and above all the business model. Examples of mechanisms such as service discovery; topology significance may be highlighted during the presentation, what may be critical is the instantiation of meta-data cross cloud providers.
The speaker is currently a JCA Cloud Chair at the ITU-T and had served as ITU-T Cloud Computing Vice Chair.
back to program ^ |
|
InstaGENI and GENICloud: An Architecture for a Scalable Testbed |
Rick McGeer, HP Labs |
|
The world of computing in the early 21st Century is dominated by very large-scale distributed systems, where high scalability and, increasingly, programmable networking with virtualized networks are critical. However, the research community currently lacks high-scale, advanced-networking testbeds to explore large-scale systems with tight network integration. Since it is infeasible for the research and education community to build facilities on commercial scale, we have focused on exploring federation as a tool to permit researchers to easily build medium- and large-scale temporary facilities from small-scale building blocks. We have been experimenting with two architectures designed to permit easy federation of multiple small-scale and medium scale facilities. The first, GENICloud, is an attempt to create an overlying API for conventional Cloud systems which can be implemented on a number of Cloud management systems; the intent is that this will permit Cloud researchers to easily instantiate networks of virtual machines on Cloud systems operated by multiple different providers, without knowing details of the underlying Cloud management systems, much as, today, a web user can access content from multiple different websites without knowing details of the underlying web server technology. We have implemented GENICloud on the PlanetLab, Eucalyptus and OpenStack control frameworks, and currently operate a multi-site Cloud facility across two continents. The second architecture, InstaGENI, is a distributed cloud based on programmable networks designed for the GENI Mesoscale deployment and large-scale distributed research projects. The InstaGENI architecture closely integrates a lightweight cluster design with software-defined networking, Hardware-as-a-Service and Containers-as-a-Service, remote monitoring and management, and high-performance inter-site networking. The initial InstaGENI deployment will encompass 32 sites across the United States, interconnected through a specialized GENI backbone network deployed over national, regional and campus research and education networks, with International network extensions to sites across the world.
back to program ^ |
|
Deeply Programmable Network for Inter-Cloud Federation |
Aki Nakao, Univ. of Tokyo |
|
This talk introduces our recent research on the network node architecture called FLARE that enables deep programmability within the network and its application for Cloud and Inter-Cloud applications. Deep programmability refers to not only the control plane programmability for route control, network management, etc., the recent SDN research deals with, but also the data plane programmability for processing traffic data and parsing new protocols, e.g., even non-Internet protocols. The FLARE architecture introduces multiple isolated programming environments where we can flexibly and deeply program innovative in-network services such as new switching logics, packet caching and DPI, and run them all concurrently at the line speed or switching among them on demand. Even a version of OpenFlow switching becomes one of the in-network services that can be programmed within the FLARE architecture. We have implemented several prototype versions of switches based on the FLARE architecture applying resource container techniques to a combination of many-core network processors and x86 general purpose processors. We discuss the capability of FLARE switches from the stand-point of enabling in-network services especially for Cloud and Inter-Cloud Federation.
back to program ^ |
 |
|
|
|
